
무한 스크롤을 사용하면 페이지를 따로 넘겨야 할 필요 없이, 즉 방해 없이 계속해서 컨텐츠를 보여줄 수 있기 때문에 유저들이 더 많은 컨텐츠를 보게 할 수 있습니다.
이런 이유 때문에 오늘의집에서도 무한 스크롤을 사용해서 컨텐츠 리스트를 구현하고 있습니다. 그러나 무한스크롤을 사용하면 '동적으로 페이지가 바뀐다'는 특성상 여러 문제점이 발생합니다. 이 글에서는 이런 문제점들을 짚고, 오늘의집에서는 어떻게 이런 문제점들을 해결하고자 했는지 설명합니다.
가장 간단한 구현 방법
무한 스크롤 유저가 페이지 바닥에 근접했을 때 내용을 더 불러와서 화면에 추가로 렌더링하는게 전부입니다. 이걸 그대로 구현한다면, 단순히 스크롤 위치를 체크해서 추가로 요청을 보내면 무한 스크롤 구현이 끝납니다.
하지만, 무한 스크롤은 본질적으로 가지고 있는 문제가 많습니다.
유저가 다른 페이지를 탐색했다가 뒤로가기를 누르면 아까 보던 위치로 돌아올 수 없다는 것이죠.
기본적으로 브라우저 스크롤 위치를 저장해주기 때문에 원래 위치로 정상적으로 돌아오게 되어 있습니다. 처음 그려지는 UI가 스크롤 위치로 갈 수 있을 만큼 높이가 충분하다면 그 위치로 바로 이동하고, 실제로 이때문에 무한 스크롤이 적용되지 않은 페이지는 정상적으로 동작합니다.
무한 스크롤로 불러온 데이터 페이지를 나갔다 돌아오면 전부 초기화되기 때문에, 브라우저가 기억했던 스크롤 위치가 이미 사라져버리고 없습니다. 즉, 아무 처리도 하지 않고 무한 스크롤을 구현하면 1페이지 맨 바닥까지만 스크롤이 이동하고 더 이상 돌아가지지 않는 것입니다.
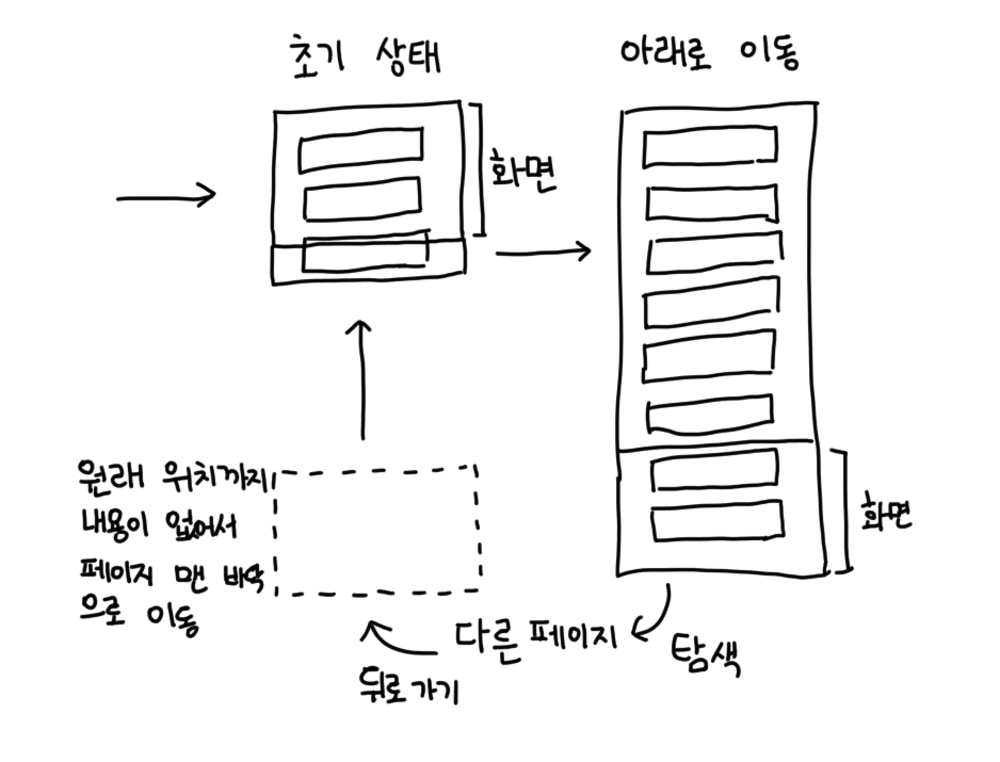
이 문제를 해결하기 위해서는 "무한 스크롤로 불러온 데이터를 삭제하지 않는다"는 쉬운 방법이 있습니다. 단순히 생각해본다면, 페이지가 바뀌지 않으면 데이터가 날라갈 이유도 없습니다. 몇몇 사이트는 창을 모달로 띄우거나 SPA인 경우 메모리에 페이지 데이터를 그대로 넣어놓는 방법으로 구현했으며, 새로고침을 하지 않으면 문제 없이 동작했습니다.
오늘의집은 무한 스크롤을 구현할 당시에는 SPA로 마이그레이션이 되지 않은 상황이었고, 따라서 필연적으로 페이지 이동이 발생하기 때문에 위에서 설명한 방법으로는 해결할 수 없는 상황이었습니다.
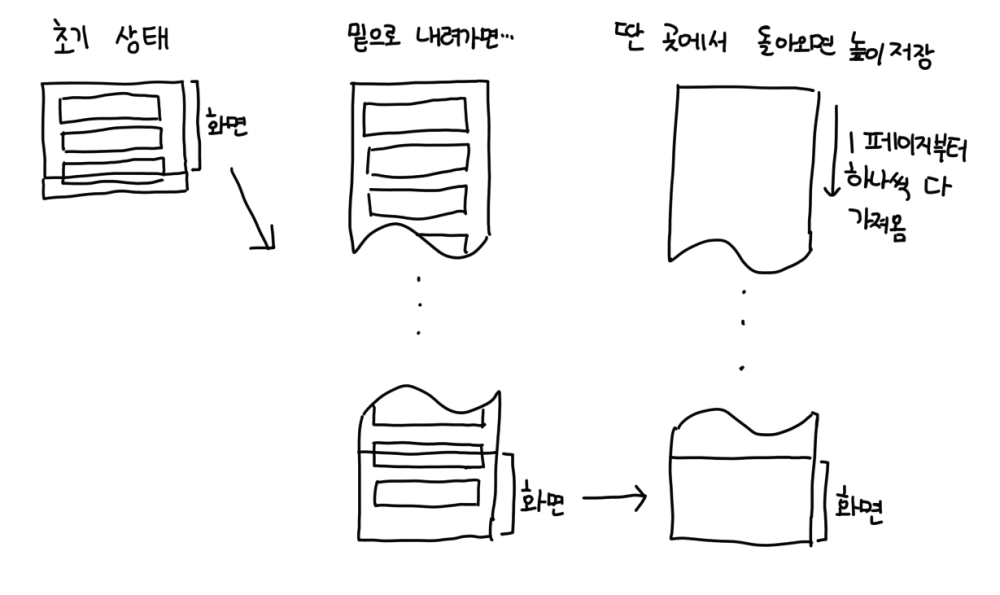
그래서 이 문제를 해결할 방법을 다시 생각해 보았습니다. 브라우저가 스크롤 위치를 되돌리려면 해당 위치까지 페이지를 만들어놓으면 되기 때문에, 세션 스토리지에 현재 최대 스크롤 높이를 기록해 놓고, 페이지를 여는 순간 padding-bottom을 그 값으로 설정하는 방법으로 이 문제를 해결해보려고 했습니다.
이렇게 구현해보았더니 원활하게 동작했습니다. 하지만 이렇게 구현하면 원하는 위치로 가기 위해서 1페이지부터 봤던 페이지까지 모든 데이터를 다시 가져와야 했고, 서버 개발자분들이 이로 인한 부담이 크지 않을까 걱정을 많이 하셨습니다.
결정적으로 너무 오래 걸렸습니다. 원하는 부분까지 보여주기 위해서는 모든 페이지들을 다 불러와야 했기 때문에, 유저가 너무 멀리 내려간 경우 그 부분까지 로딩하는데 거의 몇십초가 걸리는 정도로 이대로 사용하기는 무리가 있다고 판단하였습니다.
설상가상으로 오늘의집 콘텐츠 관리자들은 업무 스크롤을 굉장히 많이 내려서 보는 경우가 많은데, 100페이지를 넘어가면 추가로 페이지를 그리는 게 너무 오래 걸린다는 제보를 주셨습니다.
애초부터 페이지를 많이 불러오면 그 내용을 그리기 위해 DOM 노드가 많이 생기는데, 노드가 증가하면 렌더링하는 시간도 선형적으로 증가하기 때문에 '데이터를 추가로 덧붙인다'는 생각으로 접근해서는 이 문제를 해결할 수 없습니다. 대신, 유저가 보려고 하는 데이터만 불러와서 표시하는 방법이 필요했습니다. 즉 두가지 측면에서 이 문제를 접근해야 했습니다.
- 화면에 현재 표시되는 객체만, 나머지 영역은 빈 칸으로 두어서 DOM 노드 수 절약
- 유저가 실제로 보고 싶어하는 데이터만 떼어서 가져오고, 유저가 어느 방향으로든 스크롤하면 이어서 더 불러오기 가능
가상 리스트
먼저 '화면에 표시되는 객체만 그리는 것'은 기존에도 이를 위한 라이브러리가 있습니다. react-virtualized와 같은 라이브러리를 그대로 사용하는걸 고려해봤었지만, 대부분의 무한 스크롤 라이브러리들은 한 줄에 보여줄 카드 수를 렌더링하는 시점에 미리 넣는 방법으로만 구현하고 있었습니다. 오늘의집에서는 대부분의 피드가 반응형으로 한 줄에 보여줄 카드 수를 결정했었기 때문에, 이런 라이브러리를 그대로 사용하는데 문제가 있었습니다. 그래서 화면에 보여지는 항목만 렌더링하는 가상 리스트를 직접 구현하기로 했습니다.
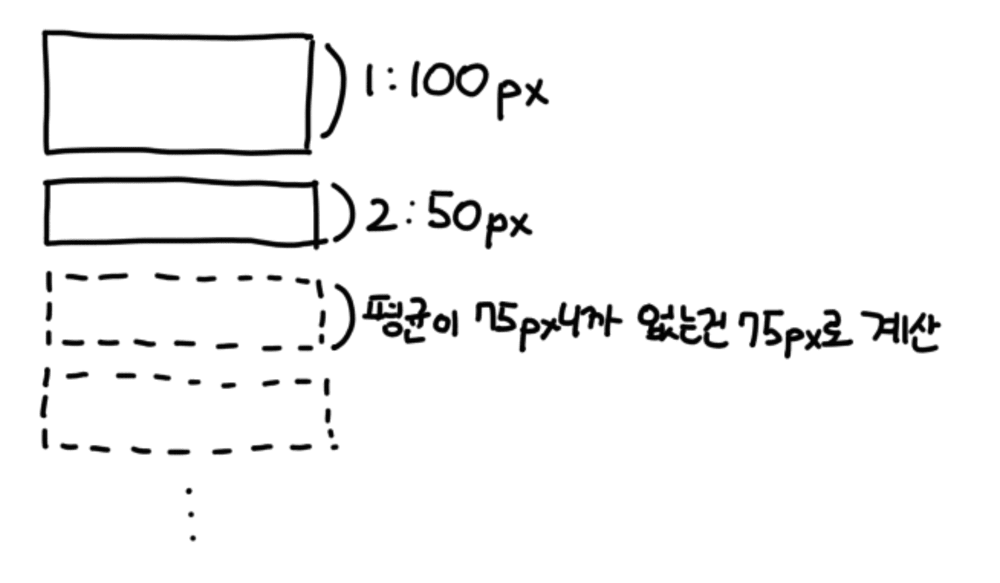
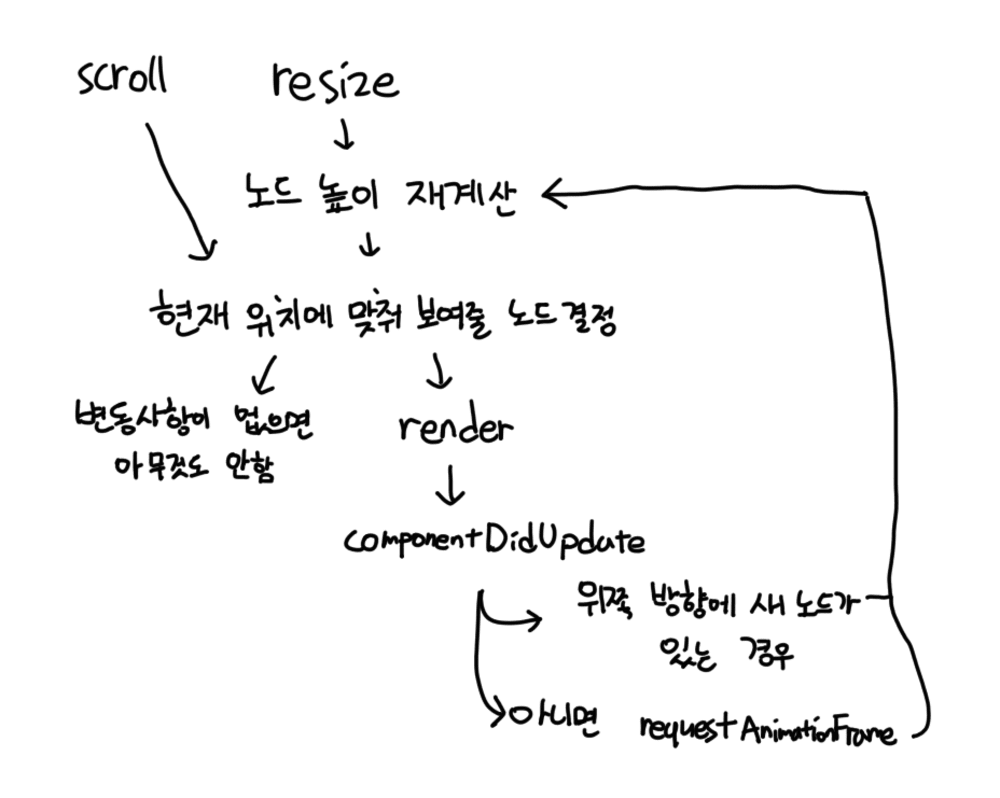
<가상 리스트>를 구현하려면 화면에 보여지고 있는 노드가 어떤 항목인지를 스크롤이 발생하거나, 페이지 리사이징이 발생하는 순간에 매번 다시 구해야 합니다. 화면에 보여지고 있는 노드가 어떤 건지 알기 위해서는 모든 노드들의 높이들을 구해서 계산해야 합니다. 실제로 대부분의 가상 리스트 라이브러리들은 노드들의 높이를 따로 집어넣을 것을 요구하고 있습니다.
하지만 오늘의집 피드의 카드들은 높이가 전부 제각각이기 때문에 높이를 고정하는 것도 불가능했습니다. 대신 여태까지 봤던 노드들의 높이를 직접 계산하고, 그 평균 높이를 계산에 사용하는 식으로 노드의 높이를 근사하는 방법을 사용해야 했습니다.
또 오늘의집 피드에서는 카드를 한 줄에 여러 개를 보여주고 있는데, 계산할 때 이 한 줄에 있는 카드들을 모두 묶어서 처리하도록 해야 했습니다. 한 줄에 3개가 있으면 3개를 전부 같이 묶어서 한 줄로 처리하는 등의 처리도 필요했죠.
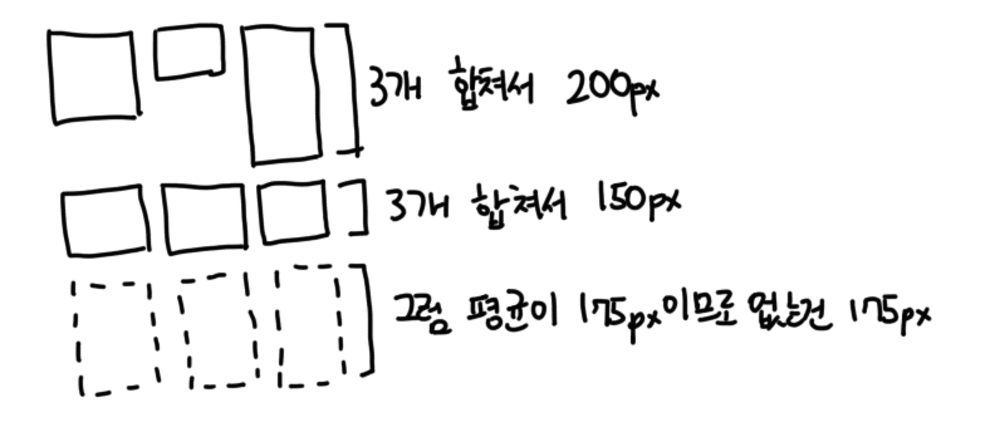
이 모든 것을 위해서는 일단 DOM에 내용을 그리고 그 데이터에 기반해서 다시 계산하는 처리가 필요했습니다. 특히 노드 높이 데이터가 없는 경우 평균값에 기반한 보여주고 있기 때문에 오차가 계속해서 발생했습니다. 이를 보정하는 로직도 필요했습니다.
화면 스크롤이 일어날 때마다 보여질 노드들을 계산해서 렌더링하고, 렌더링이 끝나면 노드 높이를 계산해서 실제 높이와 예상했던 높이가 맞는지 체크하고, 다르다면 오차값만큼 transform을 통해 보정해서 보여주는 로직을 구현해야 했습니다.
스크롤 위치를 직접 조정하고자 했지만, 브라우저의 스크롤 위치는 브라우저들이 부드러운 스크롤을 구현하기 위해서 UI 쓰레드와 별개로 비동기적으로 처리하고 있었기에 스크롤 위치를 조작하는건 불가능했습니다.
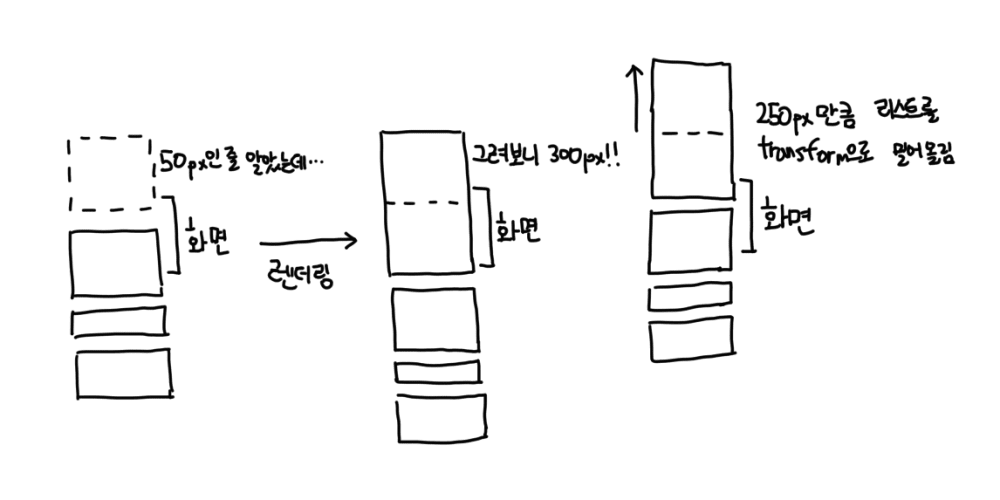
이 오차는 계속해서 누적되기 때문에 오차가 너무 커지는 경우 유저가 페이지 맨 위로 간다거나 하는 상황에서 레이아웃이 깨지는 현상도 발생합니다.

이런 문제를 해결하기 위해 유저가 스크롤을 일정 시간동안 멈추면 오차를 제거하면서 스크롤 위치를 강제로 보정하는 로직 또한 추가했습니다.
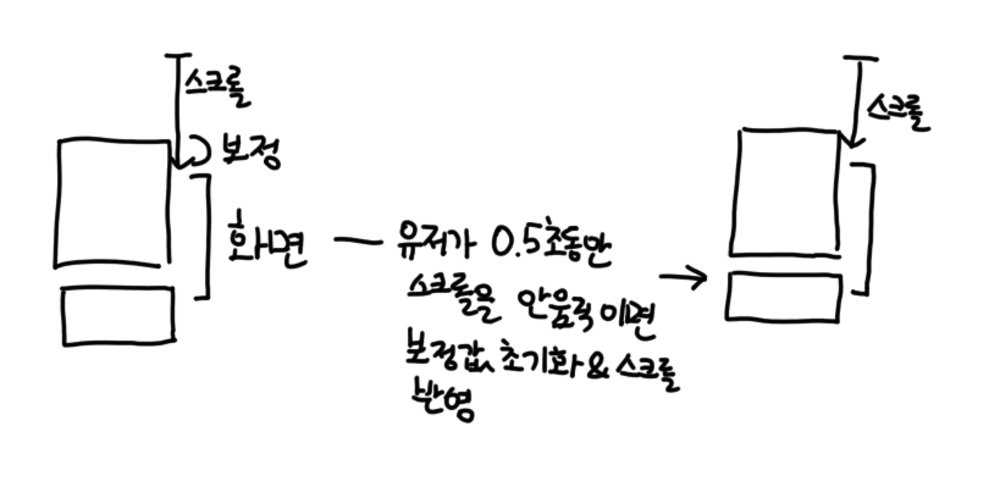
하지만 계속해서 이런 로직을 실행하면 브라우저에 부담이 많이 갔습니다. 특히 높이를 계산하기 위해서는 화면에 한 번 노드가 그려져야 하는데, 이를 기다리지 않고 바로 getBoundingClientRect를 실행해서 내용을 가져오는 경우 forced reflow가 발생하기 때문에 아예 아무 일도 하지 않고 렌더링만 기다리게 됩니다.
이런 현상을 막기 위해서는 requestAnimationFrame을 사용해서 화면에 그려지는게 완료될 때까지 기다려야 했습니다. 하지만 아래 방향에 렌더링된 적 없는 노드가 있는 경우에는 아래 방향의 노드의 높이가 어떻든 현재 화면에는 지장이 없기 때문에 기다려도 상관 없지만, 위 방향에 높이가 렌더링된 적 없는 노드가 있는 경우에는 1프레임이라도 보여주면 스크롤이 튀어보이는 현상이 일어납니다. 이 현상을 해결하기 위해 위쪽에 렌더링된 적이 없던 노드가 새로 렌더링되는 경우를 따로 체크해서, 그런 경우에는 requestAnimationFrame을 기다리지 않고 forced reflow를 의도적으로 일으키는 방법으로 깜빡이는 문제를 최소화했습니다.
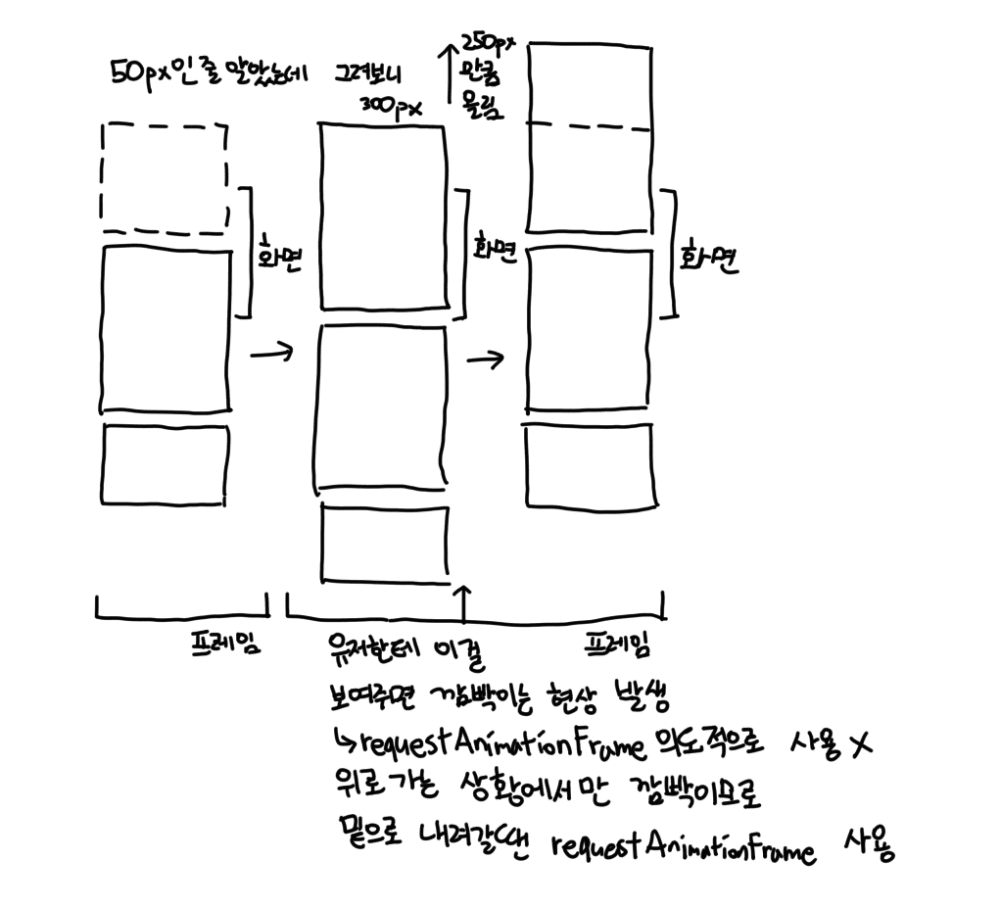
이렇게 여러가지 보정 기능을 넣어서 사용하는 시점에 노드 높이나 가로에 배치되는 노드 개수 등을 전혀 신경쓰지 않고 개발할 수 있도록 했습니다.
데이터 가져오기
앞서 말했듯이 일반적인 SPA 환경에서는 메모리에 여태까지 봤던 피드 내용을 전부 다 들고 있을 수 있기 때문에 이건 이슈가 아닙니다. 하지만 이걸 개발할 당시는 오늘의집이 SPA가 아니었기에 메모리에 내용을 들고 있을 수가 없었습니다.
페이지 내용을 전부 저장하는 대신 페이지의 커서 정보, 즉 몇 번째 페이지를 어떻게 불러왔는지에 대한 정보만 sessionStorage에 저장하도록 했습니다. 스크롤 위치만 보면 가상 리스트에서 몇번째 항목이 필요한지 알 수 있는데, 이 정보를 토대로 필요한 페이지 위치를 파악하고 필요한 페이지만 불러오도록 했습니다.
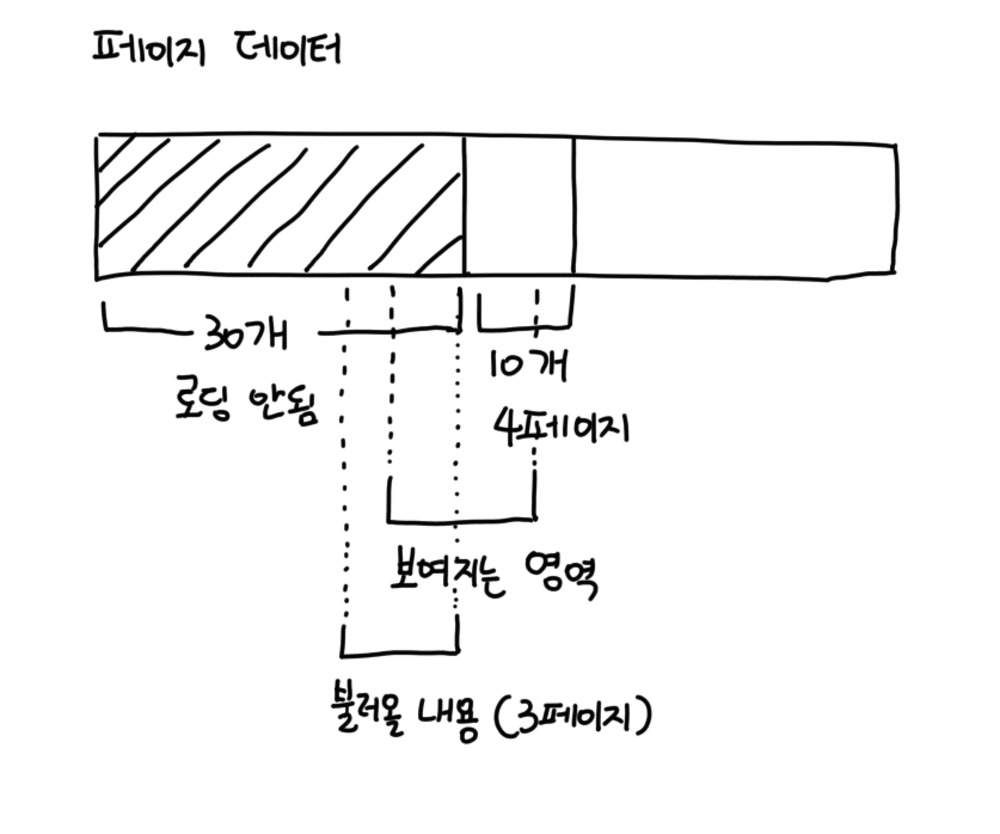
결과적으로 가상 리스트의 '화면에 표시되는 객체만 그리기'를 데이터를 가져오는 레벨까지 확장해서, 필요한 위치의 페이지만 따로 가져올 수 있도록 구현했습니다.
오늘의집에서는 여전히 페이지네이션 기반, 즉 '1 페이지', '2 페이지'와 같이 가져오는 방식을 사용하기 때문에 이렇게 구현하는게 크게 문제가 되지 않았습니다. 한편 다른 API들은 커서 기반, 즉 '다음 내용을 불러오려면 이 요청을 보내세요' 등의 방식을 사용하는 경우도 있습니다.
이런 점도 염두에 두어서 페이지네이션이 아닌 경우에는 가장 가까운 페이지의 앞/뒤 커서를 기반으로 내용을 가져올 수 있도록 했습니다.
마치며
이렇게 개발한 무한 스크롤 리스트는 피드의 큰 성능 향상을 달성할 수 있었기 때문에 오늘의집 서비스의 대부분의 피드가 무한 스크롤을 사용하도록 적용된 상황입니다. 하지만 컴포넌트 구현이 많이 복잡해졌고, 그 구현으로 인한 제약 사항도 많습니다. 예를 들어 피드 중간에 배너같은걸 삽입하고 싶다면 현재 구조로는 가로로 배치되는 노드 개수가 고정되어 있을 걸 요구하기 때문에 간단하게 넣을 수가 없습니다.
앞으로는 이런 점들을 해소하고, 더 일반화시켜서 다른 상황에서도, 예를 들면 중간에 데이터가 추가되는 상황 등에서도 문제 없이 사용할 수 있는 피드를 만들어볼 수 있으면 좋을 것 같습니다. 또, 대부분의 피드가 SPA로 구현되었기 때문에 피드 상태를 메모리에 저장하는 것도 충분히 가능해진 상황인데, 이걸 진행한다면 뒤로가기가 현재에는 서버에서 페이지를 불러오는 시간이 좀 걸리지만, 그런 시간 필요 없이 즉시 보여주게 할 수도 있을 것 같습니다.
P.S 무한 스크롤을 개발하면서 아래 글들이 굉장히 큰 도움이 되었습니다.
https://itsze.ro/blog/2017/04/09/infinite-list-and-react.html
https://developers.google.com/web/updates/2016/07/infinite-scroller