
1부. 비슷한 공간 (콘텐츠)
오늘의집은 커머스와 콘텐츠가 결합된 독특한 서비스입니다. 이로 인해 커머스와 콘텐츠 양쪽에서 방대한 이미지 데이터가 흘러 들어오고 있으며, 자연스럽게 해당 데이터를 활용하여 분석을 하거나 추천 서비스를 제공하기도 합니다. 특히 그중에서 이미지 유사도를 이용하여 유저에게 콘텐츠 추천과 상품 추천을 하고 있는데요. 이번 포스팅에서는 콘텐츠 추천을 위하여 ‘이미지 유사도’ 모델을 개발한 과정에 대해 소개하려 합니다. 참고로 분량이 길어 1부와 2부로 나누었습니다.
Goal: 주어진 인테리어 이미지와 유사한 다른 이미지 검색
오늘의집에서는 유사 이미지 검색 기술을 기반으로 크게 두 가지의 서비스를 제공하고 있습니다. 바로 유저가 선택한 사진과 비슷한 스타일의 콘텐츠를 추천해주는 ‘비슷한 공간’ 서비스와 유저가 선택한 상품과 비슷한 형태의 또 다른 제품을 소개해주는 ‘비슷한 상품’ 서비스입니다.

두 개의 서비스는 유저가 클릭한 인테리어, 상품과 비슷한 이미지를 찾아줌으로써 더 많은 탐색을 할 수 있도록 돕습니다. 이번 프로젝트를 시작하기 이전에 해당 서비스는 외부 3rd party 솔루션에 의존하고 있었으며, 저희는 아래 두 가지 지표를 충족하는 추천 시스템을 구축하는 것을 목표로 삼았습니다.
- 정성적으로 비교했을 때, 정말 비슷한 콘텐츠와 제품을 추천해주는가?
- 기존 baseline 대비 유저에게 비슷하거나 더 많은 클릭을 유도하는가?
‘비슷한 이미지’라는 것을 얼마나 잘 찾는지를 수치화하기는 매우 모호한 부분이나, 클릭 유도 성능 비교를 위해 Offline Evaluation에서 Hit Ratio(HR), Mean Reciprocal Rank(MRR) 등을 사용하고, 최종적으로 AB Test를 통해 실제 고객들의 Click Through Rate(CTR)을 비교할 수 있었습니다.
Image similarity search problem
유사 이미지 검색 문제(Image Similarity Search Problem)는 주어진 이미지와 타 이미지 사이의 유사도를 계산하여 전체 이미지 데이터 중 가장 비슷한 이미지들을 검색하는 것입니다. 먼저 두 이미지 간 유사도를 측정하는 방법부터 알아보도록 하겠습니다.
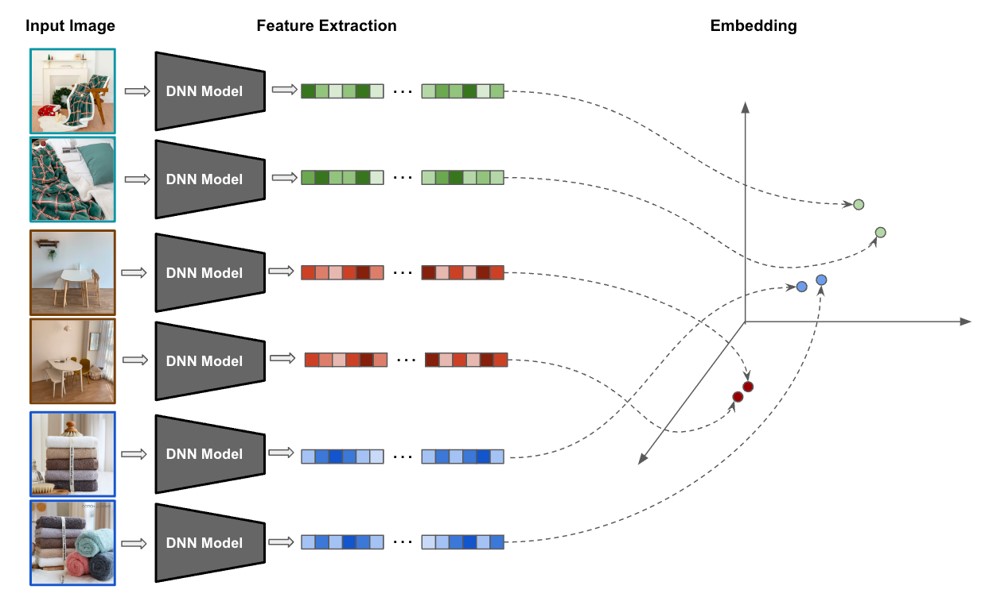
이미지 간 유사도는 각각의 이미지를 고차원 벡터로 embedding 시키고 벡터 간의 거리를 측정합니다. 이때 embedding 하는 방법을 이미지의 특징을 뽑아낸다는 의미에서 Feature Extraction이라고 칭하기도 합니다.
다양한 Feature Extraction 방식 중 이미지의 특성을 뽑아내기 위해서는 주로 Deep Learning 모델이 사용됩니다. 오늘의집에서는 콘텐츠, 커머스 등의 도메인으로 나뉘고, 그에 따라 ‘Similarity’의 정의가 달라지기에 데이터 수집 방식부터 embedding 방식이 달라져야 합니다. 따라서, 콘텐츠 추천에 대한 ‘비슷한 공간’, 상품 추천에 대한 ‘비슷한 상품’ 모델링은 각각 다른 모델로 학습하였습니다.
비슷한 공간
오늘의집 콘텐츠는 주로 인테리어, 방, 공간 등의 사진으로 구성되어 있습니다. 유저는 콘텐츠를 보면서 인테리어에 대한 영감을 얻고 선호하는 인테리어 스타일을 더 탐색하려 합니다. 따라서 저희는 ‘비슷한 공간’ 문제에서 ‘이미지 유사성’을 단순히 픽셀 단위의 유사성이 아닌 ‘비슷한 인테리어 스타일’로 정의내리고, 인테리어 스타일 분류 모델을 개발하여 콘텐츠 자동 분류 및 이미지 유사도 문제에 활용합니다.
Data 정의 및 구축
분류 문제를 정의하기 위해서는 분류에 사용할 클래스 정의가 필요하기 때문에 오늘의집 콘텐츠를 대표하는 인테리어 스타일들을 활용하여 클래스를 정의했습니다.

먼저, 분류 문제를 단순화하기 위하여 아래와 같은 케이스들을 제외했습니다.
- 혼동이 올 수 있는 경우 (예: “모던내추럴” ~ 모던, 내추럴)
- 하위 분류가 있는 경우 (예: “모던" vs. “미드센트리 모던”)
- 모수가 매우 적은 경우 (예: “럭스글램")
남은 총 11개의 스타일들을 최종 label class로 정의했습니다.
- 모던
- 북유럽
- 내추럴
- 빈티지 레트로
- 러블리 로맨틱
- 인더스트리얼
- 유니크
- 프렌치 프로방스
- 미니멀 심플
- 클래식 앤틱
- 한국 아시아
저희가 분류 문제를 풀기 위해 시도한 학습 방식은 Supervised Learning으로, 각 이미지가 11개의 클래스 중 어디에 속하는지 나와있는 정답 dataset이 필요합니다. 이때 raw dataset에 정답을 구축하는 과정을 Data Labeling이라고 합니다. 저희는 Data Labeling을 위해 Computer Vision Annotation Tool(CVAT)[1]이라는 tagging tool을 이용하여 내부적으로 태깅 환경을 구축하였고, 태깅 작업자들을 모집하여 오늘의집의 인테리어 사진을 분류했습니다.
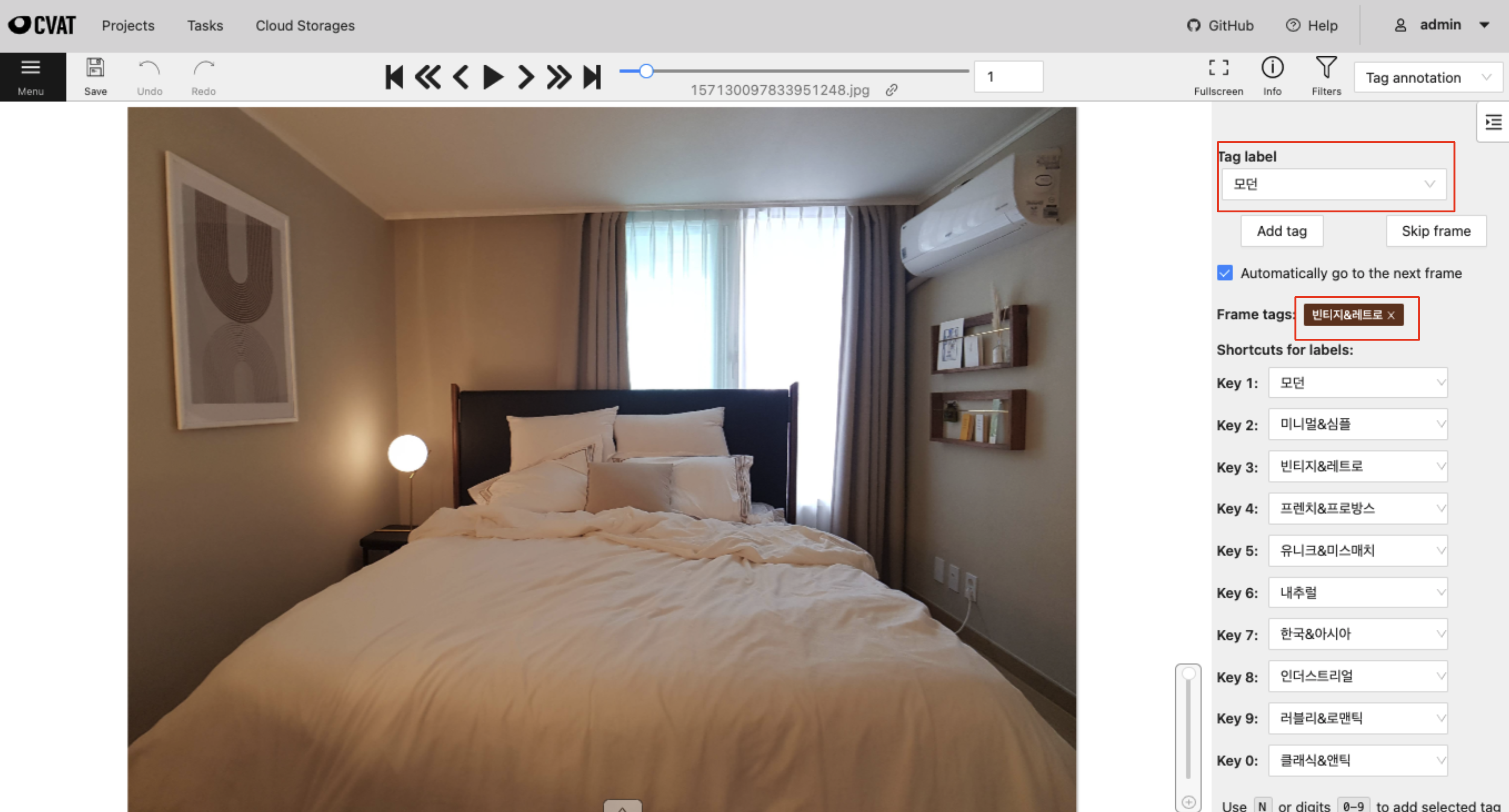
CVAT은 다양한 Computer Vision Task에 사용되는 Data Labeling Tool입니다. 분류 라벨링 시, 태깅 작업자들은 CVAT에서 할당된 사진을 보고 이미지와 가장 가까운 스타일이라고 생각하는 label을 선택합니다. 인테리어를 판단하는 기준이 사람마다 다르기 때문에, 각 스타일에 대한 판단 기준을 명확히 정의하고 작업자들을 가이드하는 일이 매우 중요합니다. 작업자들 간의 태깅 일관성을 유지하기 위해 작업자 교육 및 라벨링 데이터 검수 작업이 주기적으로 이루어졌습니다.

Classification
머신러닝에서 이미지 분류에 사용되는 알고리즘은 매우 다양합니다. 그중에서 저희가 탐색한 알고리즘은 크게 두 가지입니다.
- VGGNet
- Vision Transformer (ViT)
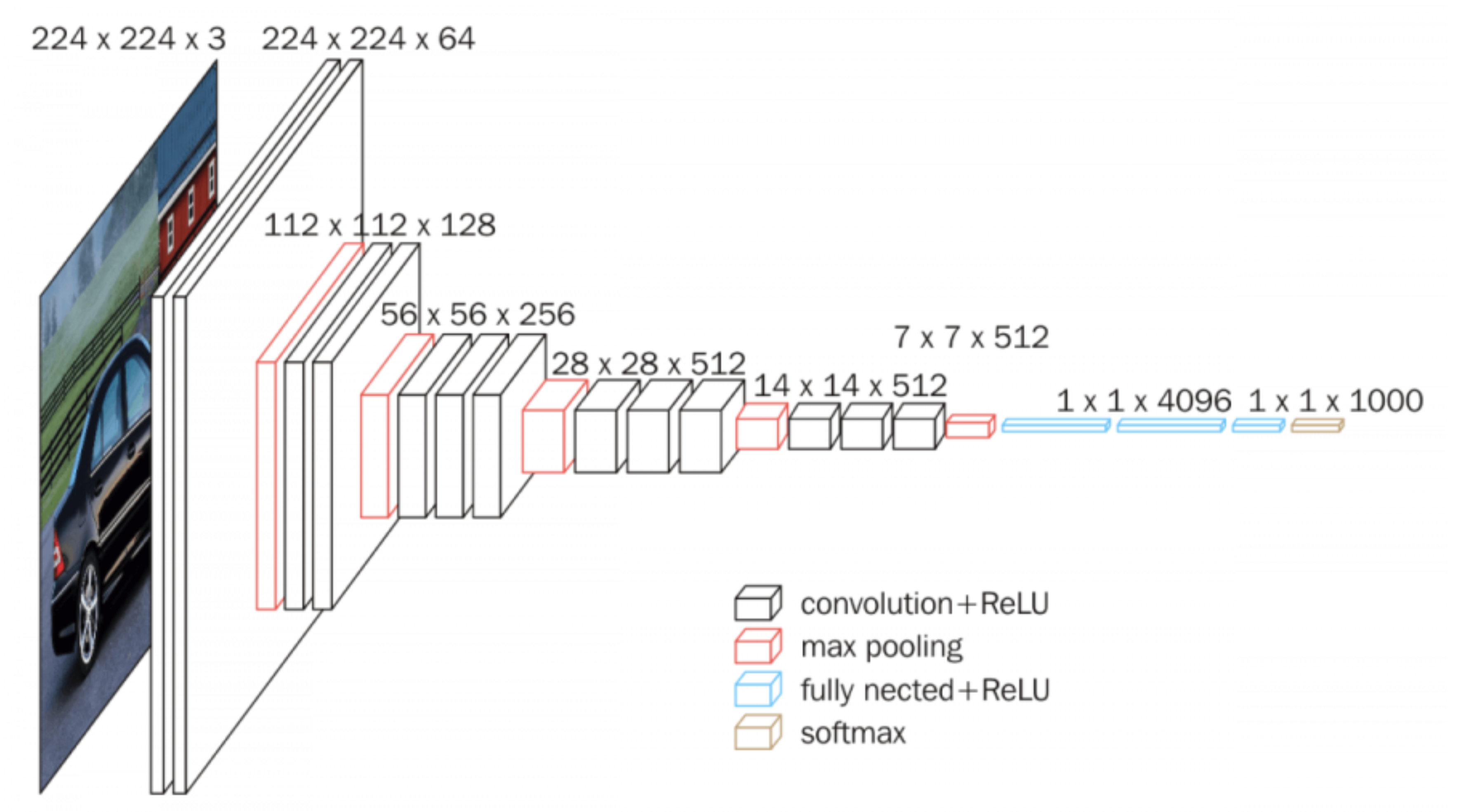
VGGNet은 2014년 ImageNet Challenge에서 준우승한 역사가 깊은 알고리즘입니다 [2]. VGGNet은 이미지 데이터에 적합한 Convolutional Neural Network(CNN) 구조를 기반으로 하는데요. Kernel의 크기를 줄이는 대신 layer를 깊게 쌓음으로써 Reception Field를 넓히는 효과로 출시 당시에 안정적으로 좋은 성능을 보인 모델입니다. 미국의 온라인 가구 배송 기업인 Wayfair에서도 VGG를 사용하여 인테리어 스타일 분류 모델을 개발한 바 있습니다 [3].
 https://paperswithcode.com/method/vgg">
https://paperswithcode.com/method/vgg">저희는 분류와 유사 이미지 추천에 대한 feasibility를 확인하기 위해 ImageNet과 Places365로 사전학습된 VGG16을 이용하였습니다. ImageNet, Places365는 이미지 분류 문제에서 자주 사용되는 대규모 이미지 dataset인데요. 특히 Places365는 침실, 카페테리아, 사무실 등 ‘공간’에 대한 정보를 가지고 있어 저희가 풀고자 하는 분류 문제와 가장 가까운 dataset이기 때문에 사전학습에 사용하였습니다. 이렇게 사전학습된 VGG16 모델에 최종적으로 약 3만 장의 오늘의집 인테리어 이미지 dataset을 사용해 전이학습(Transfer Learning)을 하였습니다.
Vision Transformer(ViT)에 대해서도 학습을 진행했습니다. ViT는 2020년 말에 발표된 비전 모델로 sequential data에 사용되는 Ttransformer를 이미지에 적용한 것입니다. ViT는 발표 당시 그동안 CNN으로 이어져 오던 이미지 분류 문제에서 새로운 State-of-the-Art Model(당시 가장 좋은 성능을 내고 있는 모델)을 차지하였고, 2023년인 현재까지도 Transformer 기반의 알고리즘이 이미지 분류 문제에서 SOTA를 유지하고 있습니다. Sequential data는 순서를 가진 데이터로 대표적으로 자연어(Natural Language), 시계열 데이터 등이 있습니다. 이미지는 물론 sequential data가 아니기 때문에 전처리가 필요한데요. 하나의 이미지를 patch라는 작은 단위로 나누어서 순서대로 정렬하면 sequential data가 생성됩니다. Patch size, model size 등을 포함한 Hyper-parameter Tuning을 통해 VGG16보다 좋은 분류 성능을 얻었습니다.
![▲ ViT 구조. source: [4]](https://res.cloudinary.com/bucketplace-co-kr/image/upload/v1684729648/%EC%9C%A0%EC%82%AC_%EC%9D%B4%EB%AF%B8%EC%A7%80_6.png)
이렇게 분류 모델 개발은 끝났습니다. 그럼 비슷한 이미지는 어떻게 찾을 수 있을까요? 이미지 간의 유사도를 계산하기 위해서는 분류 모델에서 Feature Extraction이 필요합니다. 분류 모델에서는 Classifier 바로 직전 layer에서, ViT는 Class Token에서 이미지의 1-Dimensional Representation Vector를 추출할 수 있습니다.
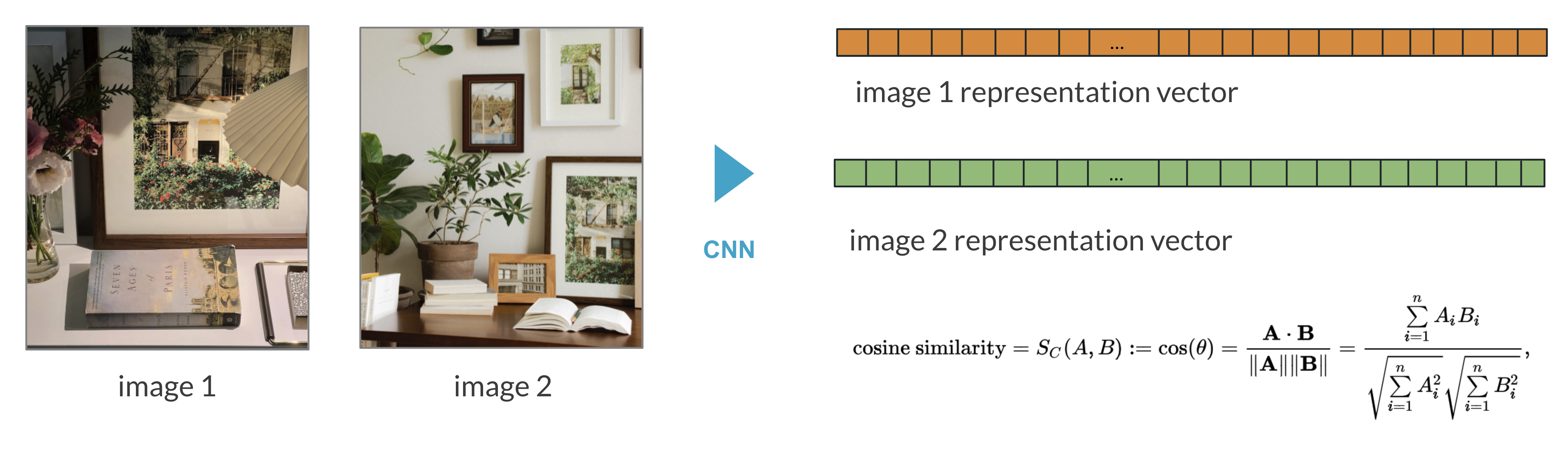
Feature Extraction 후 이미지 간 비교를 위해 두 vector간의 Cosine Similarity를 계산합니다. Cosine Similarity는 같은 방향을 가지는 vector는 1, 반대 방향을 가지는 vector는 -1을 가지는 operation으로 query image와 Cosine Similarity가 높은 순으로 정렬함으로써 비슷한 이미지를 얻을 수 있습니다. 여기서 얻은 Cosine Similarity를 가지고 인덱싱을 통해 query image에 대한 추천 결과를 줄 세우게 됩니다.
Indexing and Search
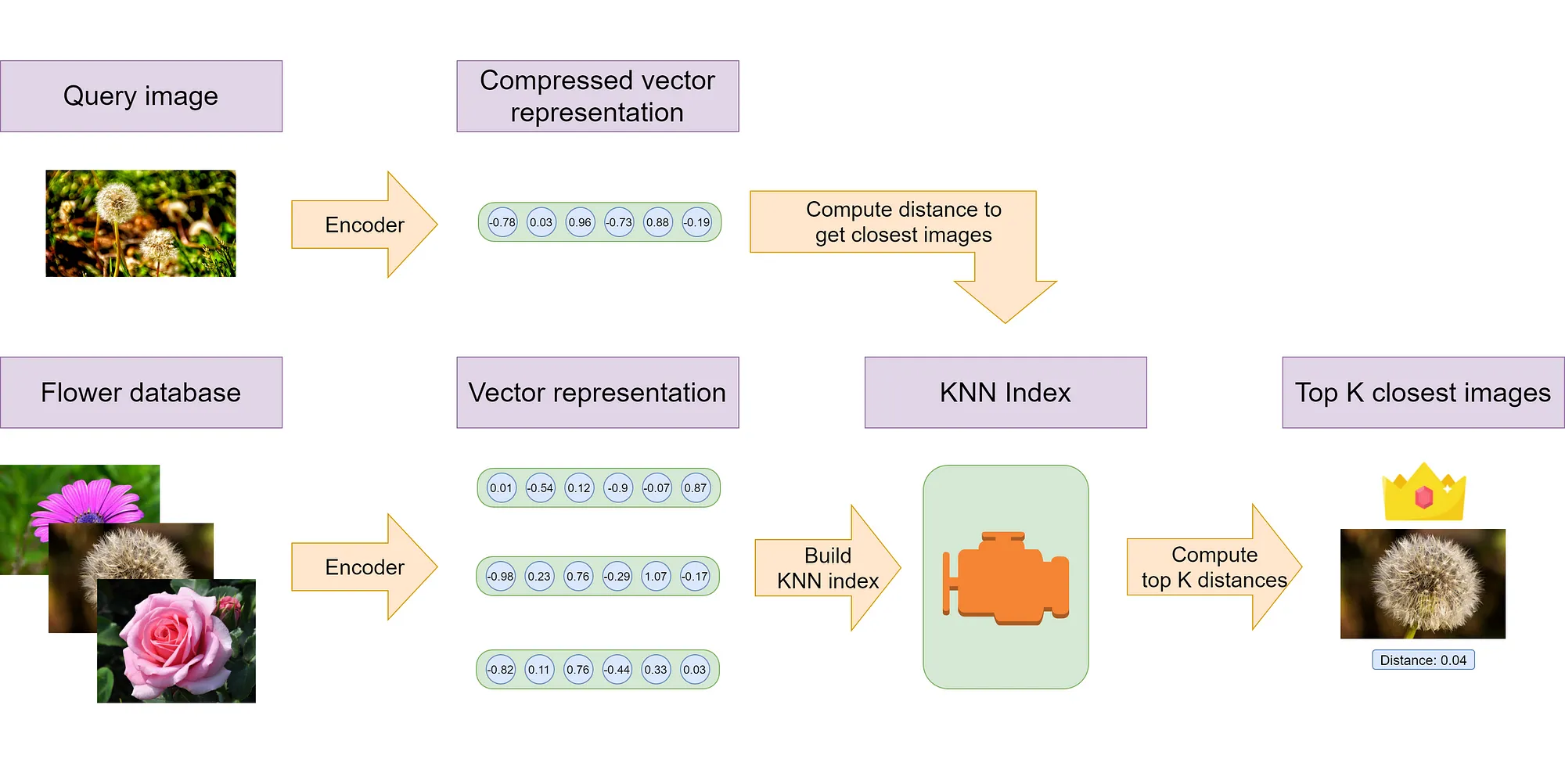
인덱싱이란 검색 효율을 높이기 위해 검색 전에 데이터베이스를 효과적으로 구성하여 쿼리에 대한 빠른 응답을 가능하게 하는 프로세스입니다. Word2vec이나 CNN 등을 통해 텍스트나 이미지 데이터를 고차원 벡터로 표현하고, 이 벡터 간의 유사성을 기반으로 가장 유사도가 높은 데이터 순으로 검색을 하게 됩니다. 검색 방법에 따라 그 효율을 높이기 위한 방법 또한 다양합니다. PCA, Normalization, Optimized Product Quantization (OPQ) 등 다양한 기법이 Vector 연산의 효율화를 위해 사용됩니다. 뒤에 소개할 Faiss 검색엔진은 Nearest Neighbor Search (NN-Search)를 기반으로 검색하고 있어 이를 위해 데이터의 양과 특성에 따라 Clustering하는 과정이 포함됩니다.
FAISS 라이브러리
Faiss(Facebook AI Similarity Search)는 이름을 통해 알 수 있듯이 Facebook AI에서 개발한 유사도 기반의 효율적인 검색을 돕는 라이브러리입니다. Faiss의 가장 큰 장점을 몇 가지 뽑자면 다음과 같습니다.
첫 번째는 심플하고 Python Language로 구현됐다는 점입니다. 마침 기존 서비스들이 Pyspark로 구현되어있었고, Faiss는 C++로 구현되어 있지만 Python에 binding 되어있어 연동에 편리함이 있습니다. 아래 예시와 같이 간단히 몇 가지 API를 통해 쉽고 빠르게 효율적인 인덱스 생성과 검색을 구현할 수 있습니다.
import faiss # make faiss available
# Indexing
index = faiss.IndexFlatL2(d) # build the index, d=size of vectors
index.add(xb) # add vectors to the index, xb contains a n-by-d numpy matrix
# Search
k = 4 # we want 4 similar vectors
D, I = index.search(xq, k) # actual search, xq is a n2-by-d matrix
두 번째는 속도입니다. 라이브러리 발표 당시, 기존 검색엔진 패키지의 성능을 유지하면서 약 8.5배 정도 빠른 성능을 보였습니다. 검색 성능과 속도는 trade-off 관계를 가질 수밖에 없습니다. 종합적인 성능이 높으면서도 앞으로 데이터가 꾸준히 늘어날 환경을 커버하기 위해서는 이 trade-off 관계를 유연하게 조절할 수 있어야 합니다.
특히 쿼리와 인덱스 크기가 점점 선형적으로 커지다 보니 brute-force하게 본다면 연산량이 exponential하게 증가할 수밖에 없어 이런 조절 없이는 시스템을 지속시키기가 어렵습니다. Faiss는 이런 데이터의 양에 따라 데이터를 적정 cell 단위로 나누어 연산하거나, Quantization, GPU 가속화 등을 Util로 제공하고 있어 search space 증가에 따른 최적화는 물론 안정적으로 시스템을 운영할 수 있는 안정적인 대처가 가능한 라이브러리입니다.
Faiss 사용 방식은 다음과 같습니다.
- Feature Extraction을 통해 이미지의 Representation Vector를 얻은 뒤 Faiss를 적용하여 추천할 이미지들의 vector에 Faiss를 적용해 인덱스를 생성합니다. (이때 검색 속도를 조정하기 위해 NN-Search 등을 적용할 수 있습니다)
- Faiss로 생성된 인덱스를 query image에 적용하면 인덱스 안에서 유사도가 높은 순서대로 이미지를 빠르게 찾아줍니다.
- Faiss 인덱스가 찾아준 검색 결과가 바로 비슷한 공간/상품의 추천 결과가 됩니다. <br> </br>
결과
이렇게 다양한 모델들을 기반으로 테스트한 결과, 내부적으로 시도하였던 첫 baseline 모델 (VGG16) 대비 test accuracy가 16% 정도 상승하는 결과를 보였습니다. ViT 모델로 AB 테스트한 결과 CTR (+2.19%), Retention (+1.11%), 인당 카드 클릭수 (+3.47%) 등 다양한 지표에서 통계적으로 더 좋은 결과를 낳았습니다. 그뿐만 아니라 click 기준으로 하루 +3.19%의 유저가 비슷한 사진 영역으로 더 유입되는 고무적인 결과를 달성할 수 있었습니다.
오늘의집 Discovery 팀에서는 이와 같은 모델링을 통해 지속적으로 유저 경험을 증진시키려고 노력하고 있는데요. 오늘 포스팅은 그중에서도 Computer Vision 모델을 통해 유저가 좀 더 원할만한 콘텐츠를 추천하는 프로젝트를 소개드렸습니다. 다음 포스팅에서는 커머스 도메인에서도 ‘비슷한 상품’을 시도한 경험을 공유하겠습니다. Stay tuned~!!
Reference
[1] CVAT, https://www.cvat.ai
[2] Very Deep Convolutional Networks for Large-Scale Image Recognition, https://arxiv.org/pdf/1409.1556v6.pdf
[3] Room Style Estimation for Style-Aware Recommendation (Wayfair, 2019), https://ieeexplore.ieee.org/document/8942313
[4] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, https://arxiv.org/pdf/2010.11929.pdf
