Introduction
오늘의집에는 다양한 종류의 콘텐츠 및 상품을 추천하는 서비스들이 있습니다. 이를 위해, 기존에는 추천이 들어가는 각 지면별로 별개의 서비스 API 를 작성했다면, 2023년도 상반기부터는 Multi-stage recommendation system을 통해 범용 시스템을 구축하여 사용하고 있습니다. 오늘 포스트는 이 서빙 시스템에 대한 소개를 하고자 합니다🙂
오늘의집 콘텐츠의 “추천 피드" 에선 다양한 타입의 콘텐츠들을 하나의 피드로 구성하여 추천합니다. 이 피드 안에는 오늘의집 유저들이 올린 사진, 영상들뿐만 아니라 집들이 / 노하우 등의 콘텐츠도 포함하고 있으며, 이런 다양한 콘텐츠를 실시간으로 추천한 후 하나의 개인화 랭킹으로 유저들에게 제공 중입니다.
오늘의집 Data & Discovery 조직 산하 추천팀에서는 2023년 상반기 이러한 추천 시스템을 만들기 위해 대규모 프로젝트를 완료했습니다. 이전에는 비슷한 공간, 혹은 비슷한 상품을 추천해 주는 각각의 시스템을 활용하고 있었다면, 이제는 하나의 Multi-Stage Recommender System을 활용하여 복잡한 개인의 니즈(Needs)에 딱 맞는 추천 서비스가 가능해졌습니다.
What is a Multi-Stage Recommender System?
Multi-Stage Recommender System은 인더스트리에서 종종 사용되는 기법이고 (Deep Neural Networks for Youtube Recommendations, ACM Conference on Recommender Systems 2016), 백만 개가 넘는 추천 후보군에서, 각 유저마다 수백 개 정도가 되는 문서나 콘텐츠를 추천하기 위해 두 개의 Stage 로 알고리즘을 나눕니다.
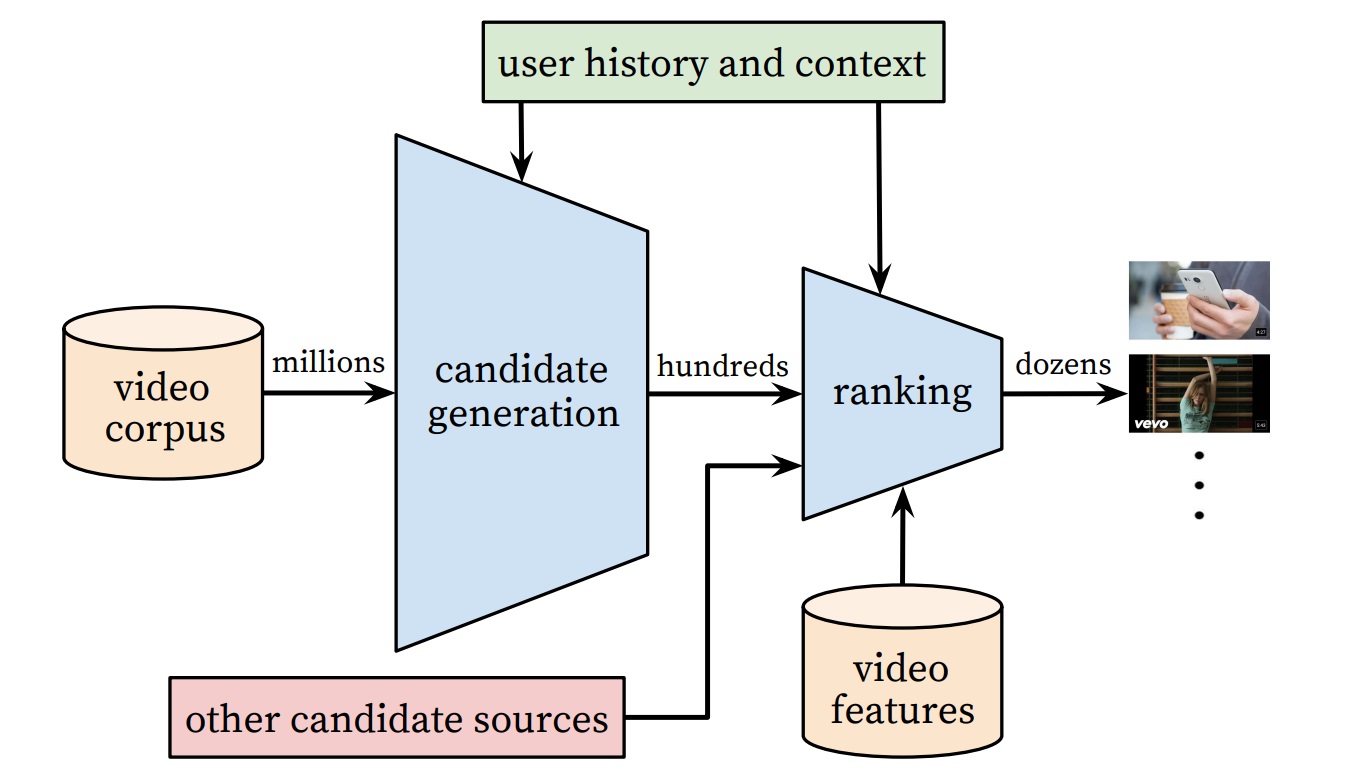
※ Source: Deep Neural Networks for Youtube Recommendations, ACM Conference on Recommender Systems 2016
첫 번째 Stage: Candidate Generation 알고리즘을 활용하여 수백만 개에 달하는 문서들 중 실제로 유저에게 추천할 만한 몇 백 개 정도의 후보군을 추출하는 작업을 합니다.
두 번째 Stage: Ranking 에 앞서 추출된 후보군들을 유저가 좋아할 만한 순서로 랭킹을 적용하는 작업을 합니다.
일반적으로 검색, 추천 등의 ML Problem에선 Precision(정밀도), Recall(재현율) 이 두 가지 지표로 시스템의 성능을 평가하게 되는데, 첫 번째 Candidate Generation 에선 유저가 좋아할 만한 문서를 최대한 많이 골라내는 Recall 을 최적화하는데 집중하고, 두 번째 Ranking stage 에선 그렇게 추려진 문서들을 유저가 좋아할 만한 순서대로 랭킹하여 Precision 을 최적화하는데 집중합니다.
이제 전체적인 문제와 어떤 알고리즘을 활용할지를 소개 드린듯하니 실제로 오늘의집 팀에서 구축한 추천 시스템에 대해 더 자세히 다뤄 보겠습니다.
Architecture Overview
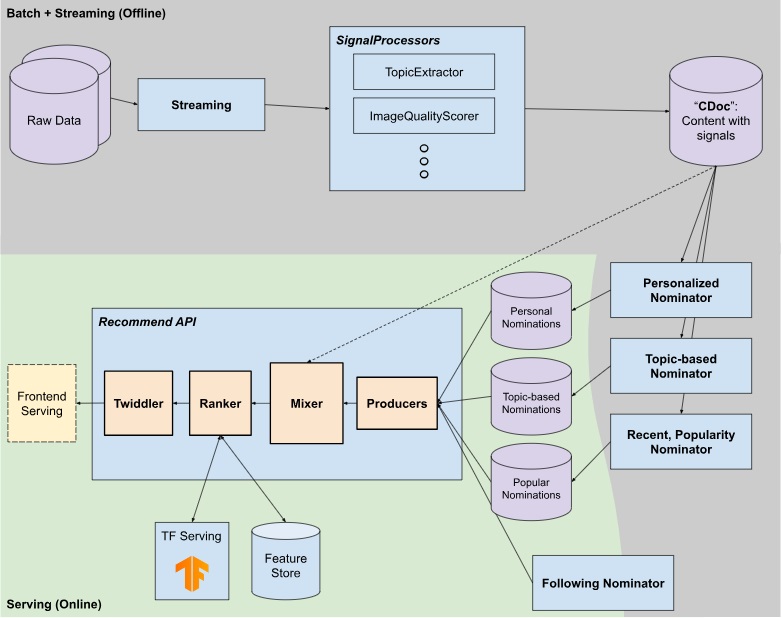
이번 포스트에서는 위 흐름도에서 Nominator 이후의 추천 시스템 구성을 주로 다룰 예정입니다.
오늘의집에서는 위 Multi-Stage Recommender System을 실시간으로 구현하기 위해 처리 과정을 Nominator, Producer, Mixer, Ranker, Twiddler의 단계로 세분화하였습니다. 또한 각 단계마다 여러 방식의 구현을 교체할 수 있도록 확장성을 고려하여 설계되었습니다. 각 단계의 역할과 자세한 내용은 다음 섹션에서 다룹니다.
Nominators & Producers
각 Nominator들은 Candidate Generation에 해당하는 알고리즘을 통해 Nomination들을 생성합니다. 다시 말해, 오늘의집에 추천 가능한 후보군 전체 중에서 유저가 좋아할 만한 후보군들을 생성하는 작업을 담당합니다.
Online vs Offline Nomination
각 Nominator는 실시간성을 띄는지, 혹은 “준 실시간성”을 띄는지에 따라 Online vs Offline Nomination으로 나뉩니다. Online nomination의 경우 팔로잉 등을 통해 유저가 직접 요청을 하는 콘텐츠이거나, 실시간 인기 혹은 큐레이션 콘텐츠 등 최소한의 검증 후 노출하고자 하는 콘텐츠에 해당합니다.
그러나 많은 케이스의 추천 알고리즘은 좀 더 많은 연산을 필요로 하기 때문에 offline nomination을 통합니다. 이 경우엔 우선 콘텐츠 자체에 대한 시그널들을 먼저 추출하는 수순이 필요하고, 이런 작업을 SignalProcessor에서 실행하게 됩니다. SignalProcessor에선 콘텐츠의 이미지 퀄리티(고품질, 저품질), 콘텐츠의 토픽들 (#데스크테리어, #강아지, ..), 콘텐츠 내의 물체들 (소파, 테이블, 텐트, ..) 등을 추출하는 알고리즘들이 실행됩니다. 이렇게 추출된 정보들이 각 콘텐츠마다 하나의 문서에 조인된 CDoc (CompositeDoc)이란 곳에 저장되게 됩니다.
이렇게 콘텐츠 자체에 대한 정보들이 담긴 CDoc이 완성되면, 해당 정보들을 사용하여 유저에게 적합한 콘텐츠를 추천하는 알고리즘들이 Nominator 안에서 비로소 실행됩니다. 이 Nominator들은 흔히 보는 collaborative filtering, graph-based recommender 등의 알고리즘을 통해 콘텐츠를 추천하기도 하고, 유저가 관심도를 보인 토픽에 해당하는 콘텐츠를 추천하기도 합니다.
이러한 nomination들은 연산량 혹은 실시간성에 따라 batch pipeline 혹은 streaming pipeline 으로 실행되고, 그 결과값인 nomination들은 서빙 가능한 저장소에 저장됩니다. 현재 오늘의집에서는 이러한 서빙 가능한 저장소에 Redis, DynamoDB 등의 NoSQL을 활용하여 Key-Value lookup 을 지원하고 있습니다. 각 Nominator 마다 리트리벌(retrieval)을 하는 방법이 상이하므로, 그에 맞는 Key-Value schema를 세팅하여 사용 중입니다.

이렇게 저장된 Nomination들을 서빙 타임에 리트리벌해 오는 컴포넌트를 Producer라 지칭합니다. 각 Nominator 마다 별도의 저장소에 후보군들이 저장되기 때문에, 서빙 타임에 리트리벌하는 Producer들은 각 Nominator마다 하나씩 존재하게 됩니다.
Mixer
이와 같이 Producer들에서 리트리벌해 온 후보군들을 하나의 리스트로 믹싱하는 작업을 Mixer에서 진행합니다. Mixer에선 다양한 알고리즘들을 적용할 수 있는데, 간단한 예로 아래와 같은 stage들을 거칩니다.
- Deduplication: 여러 Producer 들에서 가져온 Document 들은 여러 알고리즘을 통해 추천했기 때문에, 서로 겹치는 후보군들을 포함하고 있습니다. 일반적으로 피드 등에 노출될 때 이러한 중복 아이템들을 피하기 위해 dedup 오퍼레이션을 진행합니다.
- CDoc Retrieval: 앞서 말씀드린 CDoc 안에는 각 Document들마다 여러 메타정보를 미리 연산해 놓습니다. 이 CDoc들은 각 Nominator에서도 쓰일 뿐 아니라, 실시간 서빙을 할 때에도 유용하게 쓰이기 때문에, Producer들이 가져온 Document ID들에 대한 CDoc bulk retrieval을 진행합니다.
- Filter: 앞서 가져온 CDoc 안에 있는 메타정보를 활용하여 필터 처리를 합니다. 여기서 사용되는 메타정보들은 다양한데, 예를 들어 image quality score, abusing content score 등을 활용할 수 있습니다.
Ranker
이렇게 1차적으로 구성된 후보군들을 이제 랭킹을 할 차례가 되었습니다. 랭킹 알고리즘은 해당 추천이 나가는 지면의 목적성에 따라 다른 알고리즘들을 활용할 수 있게 구성되었습니다. 예를 들자면 아래의 내용들을 지원할 수 있습니다.
- RRF (Reciprocal rank fusion)
- pCTR (CTR prediction)
- Two tower model
- Sequence model
이렇게 추천된 후보들의 순위를 정하는 랭커는 간략히 설명하면 각 후보군들에 대한 정보 (CDoc 내의 정보들)와 유저들에 대한 정보 등을 Feature Store 에 저장한 후, 이를 활용해 모델 예측을 진행하는 형태입니다. 랭커에 대한 자세한 내용은 다음번 포스트에서 다뤄보도록 하겠습니다.
Twiddler
이렇게 랭킹을 마친 후보군 리스트는 추천 피드의 목적성에 맞게 최적화되어 구성됩니다. 다만, 각 지면의 복잡도 혹은 비즈니스 룰에 따라 해당 피드의 목적성을 하나의 objective function으로 표현하기 어려울 때가 종종 있습니다. 예를 들어 아래와 같은 요구사항을 고려해 보면
- 전체 랭킹은 CTR(Click-through rate; 클릭률)을 최적화하되, 상위 30개의 포지션엔 최신 콘텐츠가 50% 이상으로 노출되도록 하자.
- 피드에 동일 유저가 (혹은 판매자가) 올린 사진이 연속으로 노출되지 않도록 하자.
- 명절 관련 콘텐츠가 명절 시즌 1달부터는 상위 노출되었으면 좋겠는데, 명절이 끝난 직후엔 더 이상 노출되지 않도록 하자.
- 유저가 1번 이상 클릭이나 좋아요를 눌렀거나, 5번 이상 노출된 콘텐츠는 아래로 downranking 하도록 하자.
이렇게 복잡한 요구사항들을 하나의 모델로 해결하기 어렵기 때문에, 이러한 비즈니스 룰들은 랭킹이 끝마친 후보군 리스트를 Twiddler라는 컴포넌트를 통하여 처리합니다. 자칫 잘못하면 Twiddler들이 너무 많아져서 트래킹 하기 어려워지거나, 랭킹 모델이 Twiddler 처리가 된 아웃풋을 활용하여 학습이 되어 exposure bias되지 않도록 조심해야 합니다 – 이 부분은 사실 art와 magic의 영역이 될 수 있겠습니다😉
Server Config
이제 오늘의집에서 활용하는 추천 시스템의 기본적인 컴포넌트들을 다 보았으니, 이 컴포넌트들을 어떻게 하나로 엮는지를 간략히 설명드리고자 합니다.
추천팀에선 서버 간의 통신을 위해 gRPC를 활용하기도 하지만, 서버 내에서도 gRPC에서 사용되는 protocol buffer를 활용하여 개발하고 있습니다. Protocol buffer 는 yaml 등의 config language들과 달리 strongly typed language이기 때문에, 서버 설정에 쓰이는 textproto를 그대로 서빙 추천 서버 내에서 안전하게 활용할 수 있는 장점이 있습니다.
우선 앞서 예를 들었던 컴포넌트들을 활용하여 추천 서버 세팅을 하자면 이렇게 구성할 수 있습니다.

이를 통해 완성된 RecsConfig를 API 서버의 기본 세팅으로 두거나, 혹은 API 리퀘스트에 담아 보내면 그에 맞는 설정으로 추천 피드를 구성할 수 있게 됩니다. 이렇게 런타임에 서버 구동을 다이믹하게 바꿀 수 있는 기능을 통해 추천팀에선 AB Test 를 할 때 RecsConfig 를 바꿔가며 퀄리티 개선을 하고 있습니다.
마치며
오늘 포스트에선 오늘의집 추천 시스템에 대해 소개 드렸습니다. 앞서 설명드린 대로 다양한 제품들의 요구사항에 대응할 수 있도록 설계되었고, 첫 론칭 이후 이미 대부분의 추천 피처에 적용되어 오늘의집에서 대용량 트래픽을 받는 지면들 대부분에 활용되고 있습니다.
간략히 언급하고 넘어간 CDoc, Ranker, Feature Store 등에 대해선 추후 포스트에서 다시 찾아뵙도록 하겠습니다😀
References
[1] Youtube Deep Learning Recommendation Paper [link]
[2] Twitter Recommendation Server [link, code]
[3] Instagram Recommendation System [link]
[4] TikTok Recommendation System [link]
