
새로 산 인테리어 소품을 어떻게 배치할지 고민할 때, 우리 집과 비슷한 사이즈에서 다른 사람들은 수납을 어떻게 하는지 궁금할 때, 반려동물과 함께하는 공간을 만들고 싶을 때 어디를 탐색하시나요?
오늘의집에는 공간과 라이프스타일에 대한 영감을 얻을 수 있는 피드가 있습니다. 이 곳에서는 유저들이 직접 자신만의 공간과 노하우를 담은 다양한 콘텐츠를 공유하고 있는데요. 2014년부터 유저들이 올린 콘텐츠의 양은 이미 수천만 개를 넘어섰습니다.
오늘의집 초창기는 1인 가구 중심의 서비스였고 콘텐츠의 양이 많지 않았지만, 점차 다양한 취향을 가진 유저들이 폭발적으로 증가하면서, 유저의 관심사를 파악하고 그 관심사에 맞는 정보를 전달하기 위해 개인화 알고리즘을 통한 콘텐츠 추천을 고민하게 되었습니다.
유저가 클릭할 만한 순서로 순위 매기기 - predicted Click-Through Rate (pCTR) Ranking model
각 유저에게 맞는 개인화된 추천을 제공하기 위해서는 오늘의집 콘텐츠를 유저가 선호하는 순서로 보여주어야 합니다. 즉 개인화 랭킹 모델이 최적화할 것은 유저의 콘텐츠 “선호도"가 되는 것입니다. 유저는 오늘의집을 방문해서 클릭, 구매, 스크랩, 팔로우 등의 다양한 interaction signal들을 남기고, 흥미로운 콘텐츠나 상품을 발견했을 때 더 자세히 보기 위해서 “클릭"이라는 액션을 통해 상세 페이지로 접근합니다.
이번에 시도한 방법은 콘텐츠 피드에서 유저의 선호도를 “유저가 콘텐츠를 클릭할 확률"로 정의하고 “클릭할 확률"을 예측하는 predicted Click-Through Rate (pCTR) ranking model 개발입니다.
어떤 문제를 풀 것인가?
“클릭할 확률"을 예측하기 위해 먼저 문제를 binary regression/classification으로 정의합니다. 유저가 클릭했을 때 label에 1, 클릭하지 않았을 때 label에 0을 부여한 후 ML모델에 학습시키면 클릭 확률을 예측하는 모델이 만들어지죠.
이러한 next prediction item에 대한 click 확률을 예측하는 문제를 ctr prediction이라고 합니다. Binary classification으로 각각의 item에 대한 CTR을 독립적으로 예측하는 pointwise 방식 이외에도 두 아이템 사이의 선호도를 예측하는 pairwise, top N개의 아이템을 모두 고려하는 listwise 등의 다양한 학습 approach가 있는데요.
이번 포스트에서 소개하는 랭킹 모델에서는 연산량과 복잡도가 낮은 pointwise 방식에 대해 소개 드립니다.
어떤 Feature를 쓸 것인가?
이제 어떤 데이터를 학습시킬지 정할 차례입니다. 추천 시스템은 크게 협업 필터링(Collaborative Filtering)과 콘텐츠 기반 접근 방식로 나뉘는데 일반적으로 유저-아이템 사이의 상호작용을 학습해서 추천을 제공하는 협업 필터링의 성능이 콘텐츠 자체 데이터를 사용하는 콘텐츠 기반 시스템보다 좋은 것으로 알려져 있습니다.
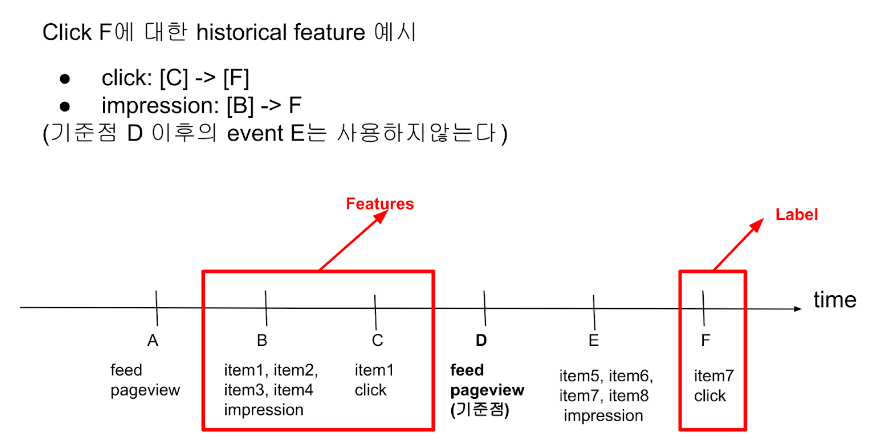
이러한 협업 필터링의 이점을 활용하기 위해서 유저가 어떤 콘텐츠에 어느 위치(position)에서 노출(impression) 되었는지, 어떤 콘텐츠를 클릭(click) 하였는지를 user history feature로 가공해서 추가하였습니다. 이때 주의할 점은 데이터의 label 또한 click 여부로 정의되므로 history feature는 label event와 연관관계가 없는 것만 사용해야 한다는 것입니다.
예를 들어 클릭 전 최신의 impression 데이터를 전부 사용하면, 클릭은 반드시 최근의 impression에서 일어나므로 모델이 최신 impression이 일어난 콘텐츠가 positive가 아님에도 불구하고 positive에 가깝게 학습해버릴 수 있습니다.
이 외에도 유저의 관심사, 최근 조회한 콘텐츠와 커머스 등의 유저 feature와 콘텐츠의 이미지와 텍스트에서 추출한 벡터 등의 콘텐츠 feature 등에 대해 ablation study(feature를 제거해봄으로써 feature가 어떤 영향을 주는지 확인하는 실험)을 진행하여 최종 feature를 선정했습니다.
어떤 모델을 쓸 것인가?
CTR 예측을 위해서 주로 쓰이는 모델 구조로는 Logistic regression(LR), Matrix factorization(MF), Graph neural Network(GNN), two tower model 등이 있습니다. 유저-아이템 간 상호작용을 학습하기에는 MF, GNN과 같은 구조들이 유용하나 LR기반의 모델과 달리 직접적인 side information 활용이 어렵고 유저-아이템 간 히스토리가 없는 경우에 예측이 어려운(cold start problem) 단점이 있습니다.
저희는 유저와 콘텐츠의 side information(예. 유저의 성별, 나이, 콘텐츠의 토픽, 조회수 등)을 좀 더 원활하게 사용할 수 있는 Logistic regression(LR) 기반의 모델을 사용하기로 정하고, DNN, Field-weighted Factorization Machines (FwFM) [1] , DeepFwFM [2] 등의 모델에 대한 offline test를 통해 어떤 모델이 우리의 피드에서 잘 작동할지 테스트해 보았습니다. Offline test는 오늘의집 유저 클릭 로그를 사용하여 모델이 출력한 랭킹이 유저의 실제 선호도와 어느 정도로 일치하는지를 확인하였고 hit ratio를 기준으로 하여 FwFM을 최종 모델로 선정하였습니다.
모델 경량화
위에서 말씀드렸듯이 다양한 CTR prediction 모델에 여러 feature와 positive/negative sample을 offline test에 시도해서 최적의 모델 구조, hyper-parameter, feature set, sampling method를 찾았습니다! 서비스에 적용하려고 보니 문제가 있네요. 유저의 다양한 관심사와 콘텐츠의 수많은 특성을 반영하려다 보니 학습 데이터 셋과 모델의 크기가 너무 커지고 말았습니다.
예를 들어 이미지와 텍스트의 특성을 뽑아내기 위해 Multimodal representation model인 KELIP(주석 추가)을 사용했는데, pretrain된 모델을 그대로 사용하다 보니 이미지, 텍스트 embedding vector 각각의 크기가 1*512가 되어버렸습니다. 모델은 정교하게 학습되었지만 실시간 서비스에 바로 적용하기에는 높은 Latency가 우려되었는데요, 이러한 문제를 해결하기 위해 시도하였던 모델 경량화 방법들을 소개합니다.
Dimensionality Reduction
KELIP에서 추출한 콘텐츠의 이미지, 텍스트 embedding vector를 concat하면 하나의 콘텐츠에 1024라는 feature dimension이 만들어집니다. dimension이 크면 클수록 많은 정보를 담을 수 있다는 장점이 있지만, 모델 학습, 추론 시 연산량이 많아지고 차원의 저주가 발생할 가능성이 커집니다. feature가 가지고 있는 정보를 충분히 보존하면서 dimension을 줄이는 많은 방식이 연구되고 있는데요, 그중에 몇 가지를 골라 시도해 보았습니다.
- mean/max pooling
- Auto Encoder
- UMAP(Uniform Manifold Approximation and Projection) [3]
결과적으로 모델 성능과 hyper-parameter 최적화의 난이도를 고려해서 Auto Encoder를 최종적으로 선택하였고 1024 dimension을 64 dimension까지 줄일 수 있었습니다.
pooling은 가장 간단한 방식이지만 모델 성능 하락 폭이 컸고, UMAP은 최적화 시 dimension을 큰 폭으로 줄일 수 있는 장점이 있지만 빠르게 변화하는 데이터에 대한 hyper-parameter 최적화에 대한 부담이 있었습니다.
Share Embedding Space
저희가 사용한 FwFM 모델을 포함해서 많은 LR 기반의 모델들은 각 feature에 대해 정해진 길이의 embedding vector를 학습함으로써 feature간의 interaction을 모델링 합니다.
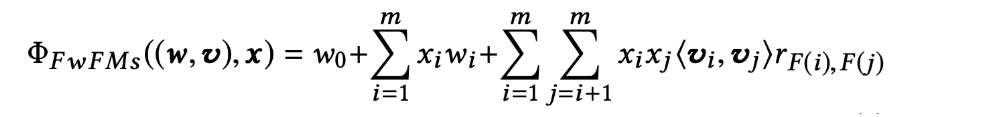
예를 들어 (categorical) feature 개수가 m개, 필드 개수가 n개, embedding space의 dimension이 K이라고 하면 학습해야 하는 파라미터의 숫자는 다음과 같이 증가합니다.
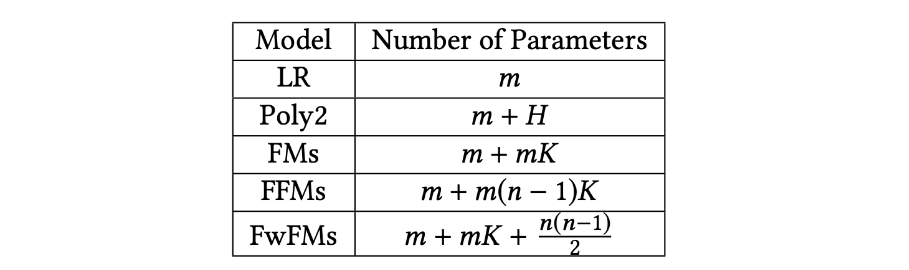
이때 비슷한 특성을 지닌 필드끼리 비슷한 embedding 방식으로 mapping될 거라는 가정 하에 embedding space를 공유함으로써 m, n의 크기를 줄일 수 있습니다.
예를 들어, historical field는 모두 콘텐츠 id로 이루어져 있으므로 같은 embedding layer를 공유함으로써 학습 파라미터의 숫자를 크게 줄일 수 있었습니다.
다만 완전히 같은 필드가 아니기에 embedding space 공유로 인해 학습 시 feature가 담고 있는 정보의 손실이 일어날 수 있습니다. 저희는 각 hash 값에 field 별로 shift를 준 후 Offline test를 통해 성능이 크게 떨어지지 않는 선에서 embedding layer를 공유하였습니다.
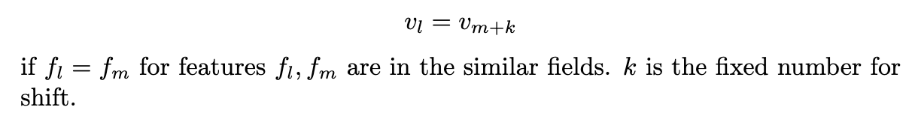
Hash 값의 범위 줄이기
feature 중에는 gender, 공간 타입 등 낮은 cardinality를 가지고 있는 경우도 있지만, 오늘의집이 가지고 있는 콘텐츠 id처럼 distinct value가 n천만이 넘어가는 경우도 있습니다. 각 distinct value에 대해 충돌을 피하기 위해서는 최대한 큰 해시테이블에 hash를 저장하는 것이 좋겠지만, 너무 많은 feature 개수로 인해 학습 파라미터의 양이 증가할 수 있습니다. 모델 성능이 크게 저하되지 않는 선에서 해시 값의 범위를 조절하여 적절한 값을 선택할 수 있습니다.
Online AB Test
이렇게 만들어진 랭킹 모델을 이제 콘텐츠 피드에 적용해 봅니다. 오늘의집의 수많은 콘텐츠에 대해서 모두 CTR을 예측하는 것은 불가능하므로 콘텐츠 개인화 추천은 크게 2가지 stage로 나뉩니다. 첫 번째 stage는 유저가 좋아할 만한 콘텐츠 후보를 가져오는 것이고 두 번째는 그 후보들을 유저가 좋아할 만한 순서대로 정렬하는 것입니다. pCTR 랭킹 모델이 적용되는 곳은 두 번째 stage인데요, 성능 확인을 위해 기존에 사용하던 휴리스틱 랭킹과의 AB 테스트를 통해 실제 온라인 성능을 비교하였습니다.
성능 비교를 위한 지표로는 유저가 콘텐츠 피드를 더 많이 조회하게 했는지 확인하게하는 Click-conversion-rate, 유저에게서 더 많은 클릭을 이끌어냈는지 확인하기 위한 CTR과 Clicks-per-user, 추천이 유저의 선호도에 따라 잘 개인화되었는지 확인하기 위한 다양성 지표인 Centrality Ratio을 사용하였습니다.
2주 간의 AB 테스트 결과 모든 지표에서 통계적으로 유의한 큰 폭의 성능 향상을 보였고 pCTR 모델 론칭 후에도 총 클릭 수와 CTR이 꾸준히 상승하는 추세를 볼 수 있었습니다.
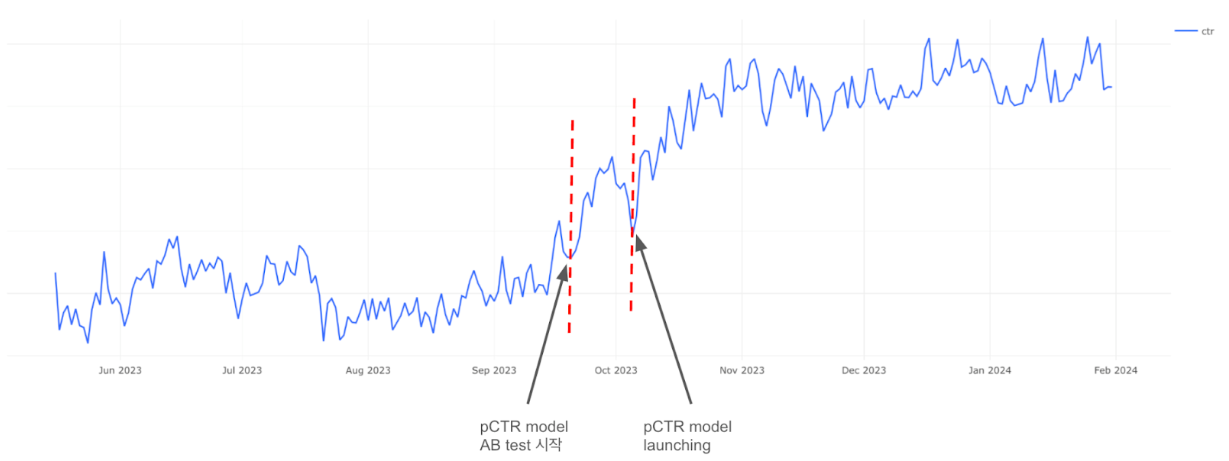
Downrank twiddler
Ranking만 하면 끝일까?
지금까지 높은 퀄리티의 콘텐츠를 상단에 보여주기 위해 Ranking에 어떤 노력을 기울였는지를 설명드렸습니다. 그 결과로 유저가 관심 가질 만한 콘텐츠가 확실히 높은 순위로 올라가는 것을 확인하였고, 과거에 비해 유저들의 반응도 좋아진 것이 확인되었습니다.
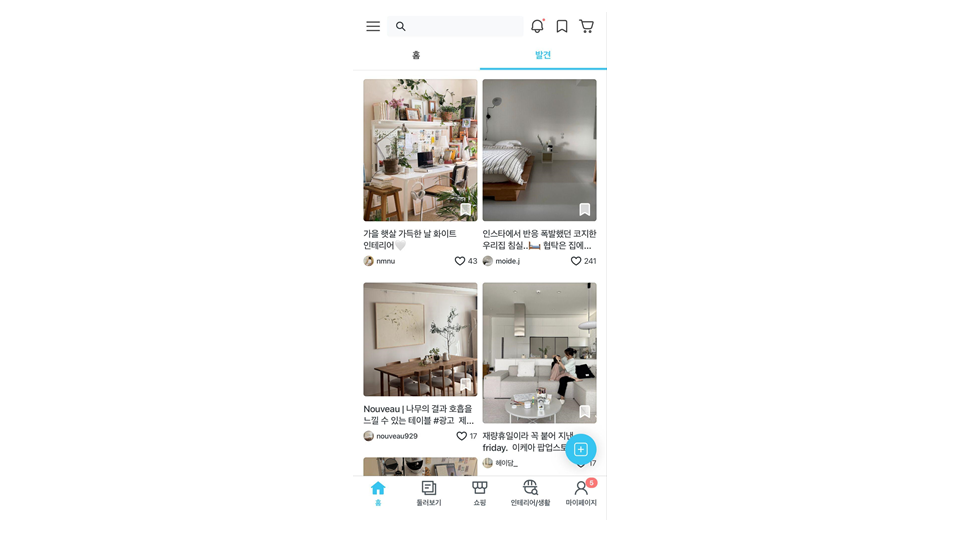
하지만 이 순서 그대로 콘텐츠를 노출해도 괜찮을까요? 여기서 콘텐츠의 퀄리티만으로 평가하기 어려운 몇 가지 문제가 발생하게 됩니다. 다음 이미지를 한번 봐주세요. 랭킹 결과를 그대로 유저에게 노출했을 때 나타나는 결과입니다.
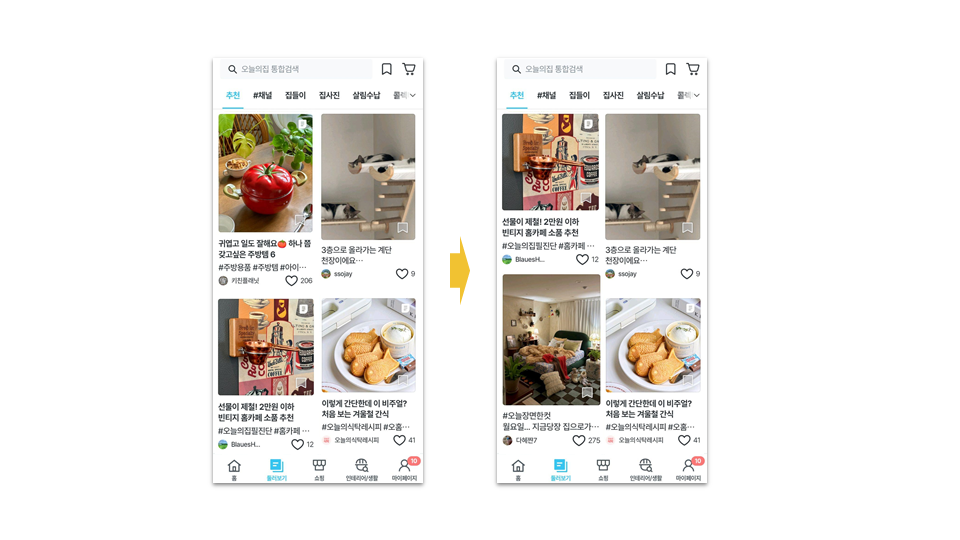
새로고침 후에도 기존 콘텐츠가 거의 그대로 유지되는 것을 확인할 수 있습니다. 단기간에 유저와 콘텐츠의 상호작용이 Ranker의 스코어를 큰 폭으로 바꾸기 힘들기 때문인데요, Ranking 결과를 후처리 없이 그대로 노출하게 되면 이렇게 유사한 콘텐츠가 반복 노출되는 문제가 생기게 됩니다. 저희는 이런 현상을 콘텐츠의 다양성이 떨어진다고 표현하고 있습니다.
물론 이러한 문제를 Ranking 단계에서 함께 고려할 수도 있습니다. 이미 유저가 본 콘텐츠를 feature로 함께 넣어서 한번 본 콘텐츠는 클릭할 확률을 낮게 계산하도록 학습을 유도해 볼 수도 있습니다. 하지만 이를 다른 랭킹과 동일한 선에서 처리하기에는 더 높은 복잡도를 지닌 모델과 보다 많은 학습량이 필요하여 현실적인 해결책이 필요했습니다.
이를 위해 저희가 사용한 방식은 Twiddler입니다. Twiddler는 Ranker가 만들어준 랭킹 결과를 사용자에게 전달하기 전에 조정해 주는 모듈입니다. 이 조정 단계에서 사용자에게 노출되었던 콘텐츠를 낮은 순위로 내려주는 과정을 거치게 됩니다. 이 과정을 Downrank라고 부르는데요. Downrank 과정을 넣음으로써 콘텐츠의 다양성을 증가시킬 수 있었습니다. 사실 Twiddler는 Downrank 이외에도 다양한 동작을 수행하는데요. 이번 글에서는 디테일한 동작보다는 Twiddler가 전체 시스템에서 어느 부분에 위치하고 있고, 어떤 식으로 동작하는지에 대한 내용을 주로 다루고자 합니다.
Twiddler를 활용한 순위 조정
전체 구조
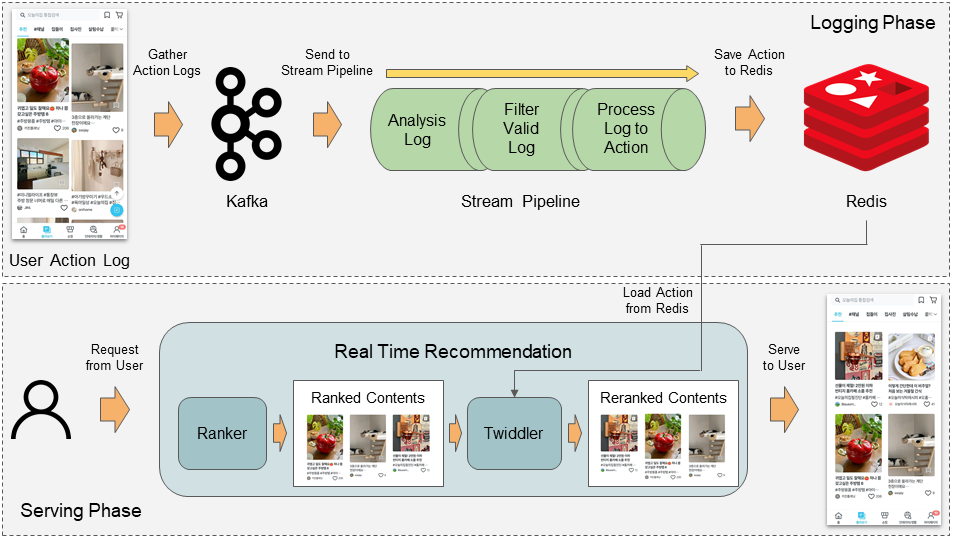
전체 구조를 먼저 설명드리겠습니다. Downrank 작업을 하는 Twiddler에서는 최근 유저에게 노출되거나 유저가 클릭한 콘텐츠의 정보가 필요합니다. 이를 위해서는 준 실시간으로 유저의 행동을 트래킹 할 수 있는 구조가 필요한데요, 저희는 Kafka와 Stream-Pipeline이라는 시스템을 통해 이 구조를 구성하였습니다.
오늘의집 애플리케이션에서 발생하는 모든 로그는 Ohouse Log라는 공통 구조를 기반으로 관리됩니다. 사용자가 애플리케이션에서 특정 동작을 수행할 때마다 로그가 발생하게 되며, 이는 로그 관리 프로세스를 통해 Kafka로 실시간 전송됩니다.
하지만 API 서버에서 직접 Kafka로 들어오는 모든 로그를 일일이 모니터링할 수는 없겠죠? Kafka로 전송된 로그를 활용하기 위해서는 로그를 실시간으로 모니터링하고 필요한 정보만 뽑아서 바로 사용 가능한 형태로 가공하기 위한 프로세스가 필요한데요. 오늘의집에서는 Stream-Pipeline이라는 시스템을 통해 이 과정을 관리하고 있습니다. 이 Stream-Pipeline을 통해 유저가 둘러보기 탭에서 소비하는 콘텐츠를 실시간으로 가공하여 Twiddler가 사용할 수 있도록 Redis에 적재하는 프로세스 구성이 가능합니다.
마지막으로 이렇게 적재된 데이터를 활용해서 Twiddler가 Ranker가 만들어준 순위를 조정하게 됩니다. 단, Ranker가 만들어준 결과를 최대한 활용하기 위해 한 가지 원칙이 있습니다. 동일한 조건을 지닌 콘텐츠 사이에서는 Ranker의 결과를 우선시한다는 원칙입니다. 이 원칙을 지키며 콘텐츠들의 순서를 조정하고 나면 이제 정말로 유저에게 보여줄 콘텐츠의 준비가 완료됩니다.
실시간 유저-콘텐츠 액션 정보 저장
이제부터는 조금 더 디테일한 프로세스를 말씀드리겠습니다. 먼저 Stream-Pipeline에서 실시간 로그를 어떻게 처리하여 적재하는지 설명드리려 합니다.
Stream-Pipeline은 유저가 애플리케이션에서 발생시킨 로그를 Kafka를 통해 실시간으로 전달받아 개발자가 활용 가능한 형태로 구성해 줍니다. 이 안에는 애플리케이션에서 일어나는 모든 로그가 포함되어 있는데요, 저희는 이 데이터 중 유저와 콘텐츠 사이의 액션 정보만을 필터링하여 활용하였습니다.
이렇게 필터링 된 정보를 모두 저장하는 것이 가장 이상적이겠지만, 네트워크 통신량과 Redis 자원을 고려했을 때 필수적인 정보만을 저장하는 형태로 파이프라인을 구성했습니다. 필수 정보에는 유저 식별자, 콘텐츠 식별자, 액션 타입, 액션 발생 시간 등이 포함되어 있으며, 자원에 대한 최적화와 다양한 플랫폼에서 파싱 리스크 없는 활용을 위해 직렬화된 protobuf 객체 형태로 저장하였습니다.
이때 Redis의 저장 자료 구조로는 Sorted Set을 활용하였습니다. Sorted Set은 Redis에서 지원하는 기본 자료구조로 Key - Score - Value 형태로 데이터를 저장합니다. 이때 데이터가 Score를 기반으로 자동으로 정렬되어 저장되므로 특정 값으로 정렬이 필요한 데이터를 관리할 때 매우 용이한데요. 저희는 액션의 Timestamp를 Score로 Sorted Set에 액션 정보를 저장하였습니다. Timestamp를 Score로 활용하면 저희가 원하는 기간만큼의 데이터만 Redis에 요청할 수 있어서 서버에서의 연산 시간을 최소화할 수 있으며, 저장된 데이터의 관리 또한 용이해집니다.
저장된 액션 정보를 활용한 Twiddler 동작
Redis에 저장된 데이터는 사용자에게 새로운 콘텐츠를 보여줄 때 Twiddler에서 활용합니다. 사용자가 콘텐츠 노출이 발생하는 화면에 진입하면 애플리케이션이 API 서버에 신규 피드 생성 요청을 보내고, 이 신규 피드 생성 요청 과정에서 Twiddler가 동작합니다.
API 서버가 신규 피드 생성 요청을 받으면 먼저 유저에게 추천할 콘텐츠를 생성하고, 생성된 콘텐츠는 위에서 언급한 Ranker를 통해 유저가 클릭할 확률이 높은 순서로 정렬됩니다. Twiddler는 Ranker의 정렬 과정과 추천 결과 서빙 사이의 마지막 레이어에서 동작합니다.
Twiddler를 통한 순서 조정에 여러 가지 요소가 고려될 수 있는데요, 이를 하나의 Twiddler에서 관리하면 한 모듈이 너무 방대한 로직을 지니게 되어 유지 보수가 어려워지고 버그 발생 가능성이 올라가게 됩니다. 확장성 면에서도 어려운 점이 많고요.
저희는 이런 문제점을 회피하기 위해 독립적으로 동작할 수 있는 로직을 각각의 Twiddler로 나누어 순차적으로 동작 가능하도록 구성하였습니다. Twiddler가 동작하는 단계를 Twiddler Layer라고 부르며, 이 Layer에는 여러 개의 Twiddler가 포함됩니다. 이 레이어의 동작은 하나의 중앙 모듈을 통해 제어되며, 이 모듈에서 필요한 트위들러를 순차적으로 적용하여 나온 결과를 사용자에게 전달 가능한 형태로 구성하게 됩니다.
Twiddler 종류
위에서 말씀드린 대로 하나의 추천 로직 상 여러 개의 Twiddler가 존재할 수 있습니다. 물론 모든 Twiddler가 항상 동일하게 사용되는 것은 아닙니다. 각 피드의 특성에 따라 특정 Twiddler가 추가되거나 사라질 수도 있으며, 동일한 Twiddler를 사용하되 피드의 특성에 따라 파라미터가 서로 다르게 들어가기도 합니다. 여기서는 대표적으로 사용되는 몇 개의 Twiddler를 예시로 들어보겠습니다.
Downrank Twiddler
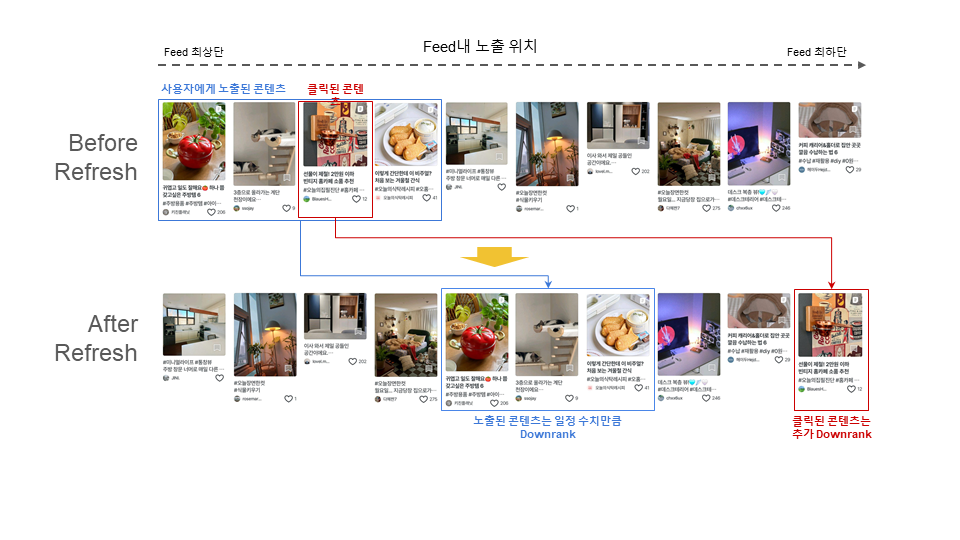
먼저 위에 예시로 들었던 Downrank Twiddler입니다. Ranker가 찾아준 클릭 가능성이 높은 콘텐츠를 찾아주고 클릭 가능성을 기반으로 내림차순 노출한다면 가장 많은 클릭을 기대할 수 있습니다. 하지만 한 콘텐츠가 반복해서 노출될수록 클릭할 가능성은 점점 낮아질 가능성이 높습니다. 이미 최근에 클릭한 콘텐츠라 관심도가 떨어지거나, 자기와 맞지 않다고 생각해서 클릭하지 않은 콘텐츠도 다시 노출될 수 있으니까요. 이러한 이유로 유저에게 한번 노출되거나 클릭한 콘텐츠는 해당 유저에게 노출되지 않게 하거나 최소한 피드의 상위에서는 제외하는 로직이 필요하지만 Ranker로만 해결하기에는 변수가 너무 많이 존재합니다.
이를 위해 Downrank Twiddler가 존재합니다. Downrank Twiddler는 Ranker에 비해 가벼운 연산량을 지니고 있고, 유저의 행동을 실시간으로 반영하여 콘텐츠의 노출 순서를 조정합니다. 유저가 이미 클릭했거나 여러 번 반복 노출된 콘텐츠는 노출 순위를 기존보다 일정 이상 낮추게 되는데요, 이 로직을 기존에 비해 Rank를 낮춘다는 의미에서 Downrank라고 부릅니다. 이렇게 유저의 클릭 확률이 낮아진 콘텐츠를 Downrank 시킴으로서 유저에게 좀 더 다양한 콘텐츠를 노출해 줄 수 있습니다.
위의 설명대로 Downrank를 시키면 간단해 보이겠지만 실제로는 어떤 경우에 Downrank가 일어날지, 어느 정도 Downrank가 필요할지, 어느 기간의 데이터를 활용할지도 고려가 필요하겠죠? 이렇게 결정이 필요한 변수 부분은 상황에 맞게 활용할 수 있도록 입력 파라미터 형태로 구성하였습니다. 파라미터로 통제 가능한 요소는 다음과 같습니다.
- Downrank 시에 고려하기 위한 행동 로그의 기간
- 각 액션별 Downrank가 일어나기 위한 기준
- 각 액션별 Downrank 정도
이렇게 Twiddler의 동작에 필요한 파라미터를 입력으로 제어 가능하게 해주면 상황에 따라 코드 수정 없이 유연한 동작 제어가 가능하다는 장점이 있습니다. 실제로 실 서비스 적용 전 AB Test를 통해 최적의 파라미터를 탐색하는 과정을 쉽게 진행할 수 있었으며, 실 서비스 적용 후에도 정책 변화에 따라 파라미터를 유연하게 조정하는 과정을 진행하고 있습니다.
Interval Twiddler

Twiddler는 Dowrank 이외의 다른 목적으로도 사용 가능합니다. 오늘의집은유사한 콘텐츠의 순위 조정을 위해서도 Twiddler를 활용합니다. 어떤 유저에게 추천된 콘텐츠 중 같은 카테고리의 콘텐츠나 동일한 유저가 올린 콘텐츠가 존재할 수 있습니다. 저희는 추천 피드에서 사용자들이 최대한 라이프 스타일에 대한 새로운 경험을 접하게 하는 것을 목적으로 하고 있는데요. 유사한 콘텐츠가 연속해서 노출되는 것은 저희의 서비스 목적에 적합하지 않아 최대한 지양하고자 합니다.
이를 방지하기 위해 Interval Twiddler가 존재합니다. 이 Twiddler는 유사한 콘텐츠를 탐색하고 유사한 콘텐츠가 최소 간격을 두고 구성될 수 있도록 순위를 조정합니다. 유사하다는 기준은 미리 입력해둔 콘텐츠의 카테고리, 작성자 등의 메타 정보를 활용하며 최소 간격은 별도 파라미터로 결정 가능하도록 구성하였습니다. 파라미터로 입력되는 최소 간격에 코드상 제한은 존재하지 않으나, 내부적으로 유저가 일정 이상 스크롤 하는 동안 유사한 콘텐츠가 노출되지 않도록 자체적으로 최소 범위를 주고 있습니다.
Future work
지금까지 Ranker가 콘텐츠를 클릭할 확률을 계산하여 콘텐츠의 순위를 결정하고, Twiddler를 통해 결정된 순위를 재조정하는 과정을 설명드렸습니다. 유저에게 개인화된 추천을 제공하기 위한 ranker, twiddler 로직은 현재도 내부적으로 많은 연구가 진행되고 있습니다. 저희가 시도한 방법들 외에도 sampling, feature, algorithm, serving 관점에서 시도해 볼 만한 다양한 approach가 있는데요, 그중에서도 오늘의집 유저가 원하는 콘텐츠를 더 정확하게 추천하는 데 도움이 될 수 있는 몇가지 future work들을 소개합니다.
Ranking
Multi-Objective Optimization
이번 개인화 추천 scope에서는 유저의 선호도를 예측하기 위해 최적화하는 objective를 CTR로 제한하였습니다. 하지만 유저의 선호도는 단순 CTR 외에도 유저가 오늘의집을 방문해서 남기는 다양한 interaction과도 관련이 있습니다! 예를 들어 A라는 유저와 B라는 유저가 똑같은 콘텐츠를 클릭했다고 하더라도 A가 콘텐츠 페이지에서 보낸 시간 대비 B가 보낸 시간이 훨씬 적거나, A가 B보다 더 많은 scrolling을 했다면 A가 B보다 콘텐츠를 더 선호한다는 근거로 사용할 수 있습니다. CTR뿐만 아니라 time, scroll on page 등을 추가적인 objective로 사용하여 유저의 선호를 더 정확하게 예측할 수 있습니다.
신규 콘텐츠 예측을 위한 Feature 추가
신규로 업로드된 콘텐츠는 유저가 콘텐츠에 대해 생성한 선호도 피드백이 부족하여 예측 성능이 저하될 수 있습니다. CTR 예측 시 신규 콘텐츠에 대해서는 유저 피드백 대신 콘텐츠 기반의 feature에 더 의존해야 하므로, 신규 콘텐츠의 속성 관련 feature를 실시간으로 추출하는 것이 중요합니다.
User/Item Representation
현재 사용하고 있는 user demography feature, content meta feature 외에도 유저, 아이템을 잘 설명하는 representation을 추가적으로 만드는 것이 개인화 추천에 도움이 됩니다. 예를 들어 유저-아이템 간 상호작용 학습에 효과적인 MF, GNN을 이용하여 user, item vector를 추출 후 pCTR 모델에 feature로 사용하거나 분석에 활용할 수 있습니다.
Model Architecture 변경
이 외에도 새로운 모델 아키텍처로 지표 및 latency 개선을 시도해 볼 수 있습니다. 예를 들어 two tower model은 vector search를 기반으로 dot product 연산을 사용하므로 추천 후보군을 가져오는 retrieval에 이점이 있어 ranking inference 시간을 줄일 수 있습니다, 또한 tower마다 specific 한 task에 fit 하도록 학습할 수 있어 랭킹 결과 분석 및 콜드스타트 문제에 활용할 수 있습니다.
Twiddler
파라미터 자동 결정
현재는 자체적인 실험을 통해 Twiddler의 파라미터를 결정하고 있습니다. 다만 실험에는 한계가 있고, 시간이 지나면서 데이터나 사용자의 특성이 변화하므로 완벽한 해결책이라고 할 수는 없습니다.
이를 근본적으로 해결하기 위해서는 최근 데이터 동향에 맞는 최적의 파라미터 결정이 필요한데요, 이를 위해 online learning 혹은 주기적인 배치를 통한 최적의 파라미터 탐색 등을 추가하여 지속적인 성능 유지가 가능합니다.
Twiddler 동작의 유연화
현재는 비즈니스 로직이 추가되고 신규 기능이 필요해질 때마다 Twiddler의 코드 작업이 필요합니다. 이로 인해 코드의 복잡도가 점점 올라가고, 비즈니스 로직이 반영되는데 시간이 오래 소모됩니다.
이를 개선하기 위해 간단히 로직을 구성할 수 있는 스크립트 코드를 삽입하는 형태로 구성하면 Twiddler 동작을 유연하게 구성할 수 있고, 신규 로직이 필요해질 경우 코드 수정 없이 빠르게 대응할 수 있습니다.
다만 이러한 로직은 머신 환경에 영향을 받을 수 있으며, 전체 프로세스의 Latency를 증가시킬 가능성이 있습니다. 이러한 점을 고려하여 부작용을 최소화하는 방향의 개발이 필요합니다.
마치며
앞에서 포스팅한 Multi-Stage Recommender System은 개인화 추천을 위한 전반적인 서빙 시스템에 대해 설명드렸다면 이번에는 ranker와 twiddler라는 추천 시스템의 component를 통해 어떻게 추천 결과를 최적화하는지에 대해 알려드렸습니다. 유저들이 서비스를 이용하면서 원하는 것을 좀 더 편리하게 찾고, 새로운 발견을 할 수 있도록 오늘의집의 추천 시스템은 계속해서 발전할 예정입니다. Stay tuned~!
Reference
[1] Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising
[2] DeepLight: Deep Lightweight Feature Interactions for Accelerating CTR Predictions in Ad Serving
[3] UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
